MIT 6.S081lecture笔记
![[Pasted image 20250305210706.png]]
LECTURE 1
系统调用
![[file-20250308111825647.png]]
fork
1.8 fork系统调用 | MIT6.S081
我们调用了fork。fork会拷贝当前进程的内存,并创建一个新的进程,这里的内存包含了进程的指令和数据。之后,我们就有了两个拥有完全一样内存的进程。fork系统调用在两个进程中都会返回,在原始的进程中,fork系统调用会返回大于0的整数,这个是新创建进程的ID。而在新创建的进程中,fork系统调用会返回0。所以即使两个进程的内存是完全一样的,我们还是可以通过fork的返回值区分旧进程和新进程。
fork创建了一个新的进程。当我们在Shell中运行东西的时候,Shell实际上会创建一个新的进程来运行你输入的每一个指令。所以,当我输入ls时,我们需要Shell通过fork创建一个进程来运行ls,这里需要某种方式来让这个新的进程来运行ls程序中的指令,加载名为ls的文件中的指令(也就是后面的exec系统调用)。
exec wait
1.9 exec, wait系统调用 | MIT6.S081
int main(int argc,char * argv[])
//命令行参数数量(包括程序名本身)
//命令行参数的字符串
![[XV6-Chinese-2020.pdf#page=8&rect=88,81,518,160&color=yellow|XV6-Chinese-2020, p.8]]
exec(“echo”,argv)
从指定的文件echo读取并加载指令,并替代当前调用进程的指令,替换了当前进程的内存,加载新指令。argv为命令行参数
比如a
char * argv[]={“echo”,”this”,”is”,0};
先从echo文件加载指令替换当前进程的内存,在执行新加载的指令,等价于
echo this is
有关exec系统调用,有一些重要的事情,
exec系统调用会保留当前的文件描述符表单。所以任何在exec系统调用之前的文件描述符,例如0,1,2等。它们在新的程序中表示相同的东西。
通常来说exec系统调用不会返回,因为exec会完全替换当前进程的内存,相当于当前进程不复存在了,所以exec系统调用已经没有地方能返回了,只有出错的时候才会返回,压根没有这个文件就会返回-1
也就是说,先fork一个子进程,再exec掉子进程,执行指令,如果直接用shell进程调用exec,系统控制权就拿不回来了(exec直接把原进程覆盖掉了)
wait
![[XV6-Chinese-2020.pdf#page=8&rect=87,347,508,410&color=yellow|XV6-Chinese-2020, p.8]]
wait会等待之前创建的子进程退出。比如说在shell里等待指令执行完成。
Unix中的风格是,如果一个程序成功的退出了,那么exit的参数会是0,如果出现了错误,那么就会像第17行一样,会向exit传递1。所以,如果你关心子进程的状态的话,父进程可以读取wait的参数,并决定子进程是否成功的完成了。
wait 等待第一个子进程退出,wait会返回,如果要等待两个子进程都退出,那你就需要两个wait
由于exec的特性,如果fork先拷贝了父进程的所有内存,exec再整个丢掉,这很浪费,需要优化
###I/0
1.10 I/O Redirect | MIT6.S081
![[XV6-Chinese-2020.pdf#page=9&rect=91,260,512,338&color=yellow|XV6-Chinese-2020, p.9]]
每个进程都有一个从0开始的文件描述符私有空间;
按照约定,一个进程从0(标准输入)读取数据,从1(标准输出)写入输出,向2(标准错误)写入错误信息;
文件描述符
本质上对应了内核中的一个表单数据。内核维护了每个运行进程的状态,内核会为每一个运行进程保存一个表单,表单的key是文件描述符。这个表单让内核知道,每个文件描述符对应的实际内容是什么。这里比较关键的点是,每个进程都有自己独立的文件描述符空间,所以如果运行了两个不同的程序,对应两个不同的进程,如果它们都打开一个文件,它们或许可以得到相同数字的文件描述符,但是因为内核为每个进程都维护了一个独立的文件描述符空间,这里相同数字的文件描述符可能会对应到不同的文件。
虽然fork复制了文件描述符表,但是每个底层文件的偏移量都是父子共享的
read write
第一个参数是文件描述符,指向一个之前打开的文件。Shell会确保默认情况下,当一个程序启动时,文件描述符0连接到console(控制台)的输入,文件描述符1连接到了console的输出。所以我可以通过这个程序看到console打印我的输入。当然,这里的程序会预期文件描述符已经被Shell打开并设置好。这里的0,1文件描述符是非常普遍的Unix风格,许多的Unix系统都会从文件描述符0读取数据,然后向文件描述符1写入数据。
文件描述符
0 从控制台输入,1控制台输出,2,错误
read的第二个参数是指向某段内存的指针,程序可以通过指针对应的地址读取内存中的数据,这里的指针就是代码中的buf参数。在代码第10行,程序在栈里面申请了64字节的内存,并将指针保存在buf中,这样read可以将数据保存在这64字节中。
read的第三个参数是代码想读取的最大长度,sizeof(buf)表示,最多读取64字节的数据,所以这里的read最多只能从连接到文件描述符0的设备,也就是console中,读取64字节的数据。
read的返回值可能是读到的字节数,在上面的截图中也就是6(xyzzy加上结束符)。read可能从一个文件读数据,如果到达了文件的结尾没有更多的内容了,read会返回0。如果出现了一些错误,比如文件描述符不存在,read或许会返回-1。在后面的很多例子中,比如第16行,我都没有通过检查系统调用的返回来判断系统调用是否出错,但是你应该比我更加小心,你应该清楚系统调用通常是通过返回-1来表示错误,你应该检查所有系统调用的返回值以确保没有错误。
read,write系统调用,它们并不关心读写的数据格式,它们就是单纯的读写,而copy程序会按照8bit的字节流处理数据,你怎么解析它们,完全是用应用程序决定的。所以应用程序可能会解析这里的数据为C语言程序,但是操作系统只会认为这里的数据是按照8bit的字节流。
shell 重定向
向shell输入内容 相当于告诉shell运行相应程序
输出重定向 ls > out
grep x < out
编译器与系统调用?ecall(environment call),特权指令,允许用户态程序请求操作系统内核的服务,将控制权交给内核。
close
close系统调用会释放一个文件描述符,使它可以被以后的open,pipe,dup等所重用;新分配的文件描述符总是当前进程中最小的未被使用的描述符
![[XV6-Chinese-2020.pdf#page=10&rect=80,62,520,302&color=yellow|XV6-Chinese-2020, p.10]]
open
![[XV6-Chinese-2020.pdf#page=11&rect=88,592,510,650&color=yellow|XV6-Chinese-2020, p.11]]
open(“output.txt,标志位)
open系统调用,将文件名output.txt作为参数传入,第二个参数是一些标志位,用来告诉open系统调用在内核中的实现:我们将要创建并写入一个文件。open系统调用会返回一个新分配的文件描述符,这里的文件描述符是一个小的数字,可能是2,3,4或者其他的数字。
之后,这个文件描述符作为第一个参数被传到了write,write的第二个参数是数据的指针,第三个参数是要写入的字节数。数据被写入到了文件描述符对应的文件中。
dup
![[XV6-Chinese-2020.pdf#page=11&rect=86,75,509,230&color=yellow|XV6-Chinese-2020, p.11]]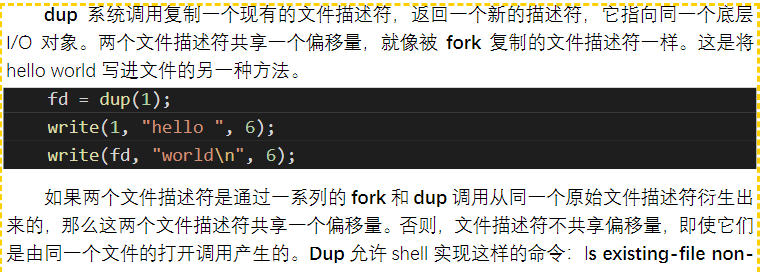
dup复制的文件描述符跟原来的一样,共享一个偏移量,就像fork复制的文件描述符一样。
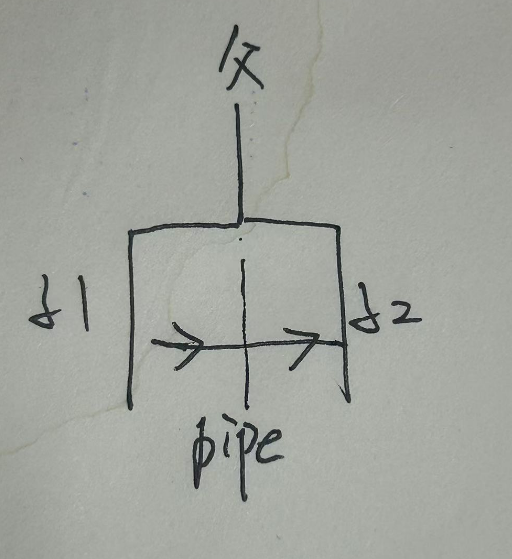
管道
管道是一个小的内核缓冲区,作为一对文件描述符暴露给进程,一端读一端写,为进程间提供了一种通信方式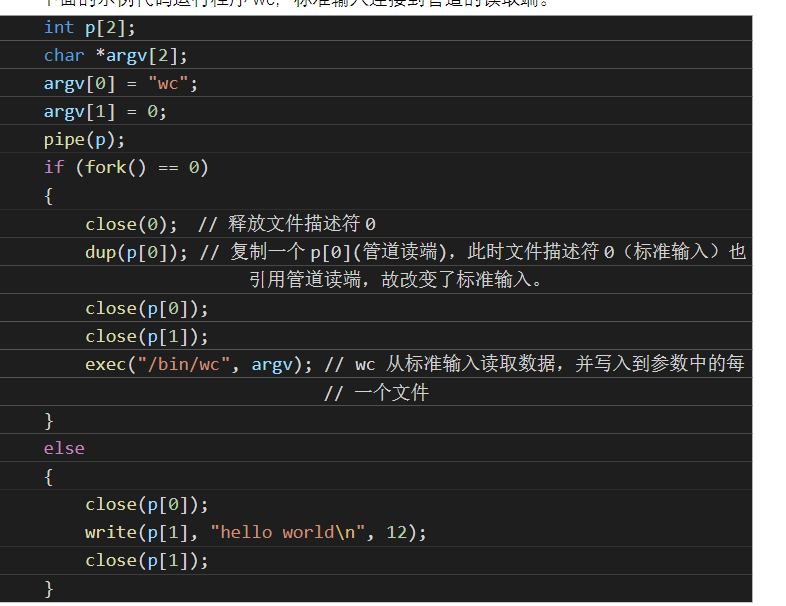
上文提到,close系统调用会释放一个文件描述符。
则此时dup(p[1])复制出的新文件描述符会被分配到0,即该进程的标准输入,这样就实现了父子进程通信;
要注意关闭管道的两端
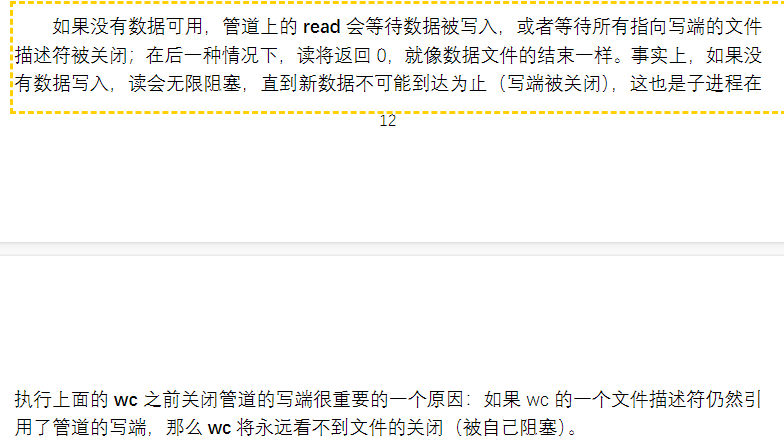
xv6 源码解读
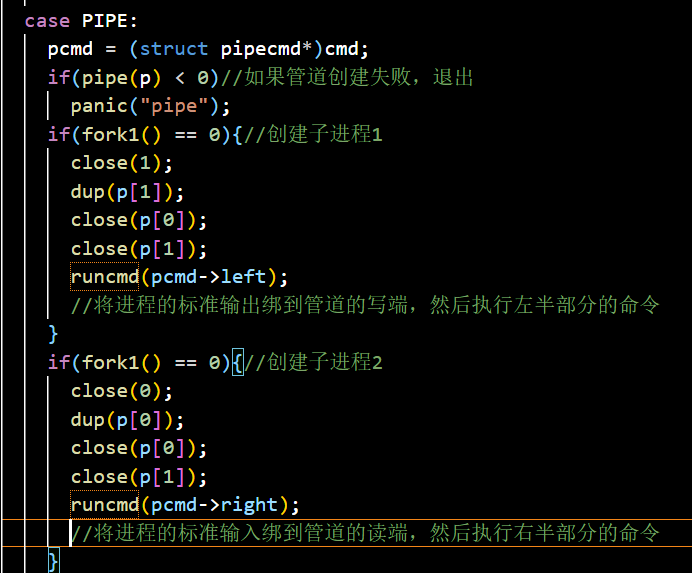
类似于ls | grep命令的实现
chdir
类似linux的cd,改变当前进程的目录
mkdir
创建一个新的目录
mknod
创建一个新的设备文件
inode 索引节点

fstat
从文件描述符应用的inode中检索信息,定义在stat.h的stat结构中
link
创建引用同一个inode的文件
link(‘a’,’b’)
访问a,b的效果是一样的;
unlink
从文件系统中删除一个文件名,只有文件的链接数为0且没有文件描述符引用它时,该文件才会被彻底删除;
LECTURE 3
一个操作系统必须满足三个要求:多路复用,隔离和交互
操作系统隔离性:3.2 操作系统隔离性(isolation) | MIT6.S081
原因
这里的核心思想相对来说比较简单。我们在用户空间有多个应用程序,例如Shell,echo,find。但是,如果你通过Shell运行你们的Prime代码(lab1中的一个部分)时,假设你们的代码出现了问题,Shell不应该会影响到其他的应用程序。举个反例,如果Shell出现问题时,杀掉了其他的进程,这将会非常糟糕。所以你需要在不同的应用程序之间有强隔离性*。
类似的,操作系统某种程度上为所有的应用程序服务。当你的应用程序出现问题时,你会希望操作系统不会因此而崩溃。比如说你向操作系统传递了一些奇怪的参数,你会希望操作系统仍然能够很好的处理它们(能较好的处理异常情况)。所以,你也需要在应用程序和操作系统之间有强隔离性。
通常来说,如果没有操作系统,应用程序会直接与硬件交互。比如,应用程序可以直接看到CPU的多个核,看到磁盘,内存。所以现在应用程序和硬件资源之间没有一个额外的抽象层。这对于隔离不是一个很好的设计。
实现 multiplexinf(cpu在多进程同分时复用) ,内存隔离
例子
协同调度:如果是一个shell里有个死循环的程序,shell永远都不会释放cpu

内存
如果没有隔离,两个应用程序的内存之间都没有边界,直接写在物理内存里。程序的内存可能会相互覆盖
设计:接口被进行设计,抽象了硬件资源,实现强隔离和多路复用;
fork
:进程抽象了cpu,应用程序只能和进程交互;这样操作系统才能在多个应用程序之间复用一个或者多个CPU。
cpu被分时复用,CPU运行一个进程一段时间,再运行另一个进程。
exec:
认为exec抽象了内存。当我们在执行exec系统调用的时候,我们会传入一个文件名,而这个文件名对应了一个应用程序的内存镜像。内存镜像里面包括了程序对应的指令,全局的数据。应用程序可以逐渐扩展自己的内存,但是应用程序并没有直接访问物理内存的权限,例如应用程序不能直接访问物理内存的1000-2000这段地址。不能直接访问的原因是,操作系统会提供内存隔离并控制内存,操作系统会在应用程序和硬件资源之间提供一个中间层。exec是这样一种系统调用,它表明了应用程序不能直接访问物理内存。
files
另一个例子是files,files基本上来说抽象了磁盘。应用程序不会直接读写挂在计算机上的磁盘本身,并且在Unix中这也是不被允许的。在Unix中,与存储系统交互的唯一方式就是通过files。Files提供了非常方便的磁盘抽象,你可以对文件命名,读写文件等等。之后,操作系统会决定如何将文件与磁盘中的块对应,确保一个磁盘块只出现在一个文件中,并且确保用户A不能操作用户B的文件。通过files的抽象,可以实现不同用户之间和同一个用户的不同进程之间的文件强隔离。
操作系统防御性:3.3 操作系统防御性(Defensive) | MIT6.S081
需要强大的隔离
硬件隔离:supervisor mode/kernel mode page table virtual memory
机器模式 machine mode
在该模式下执行的指令有完全的权限,主要用于配置计算机,然后转为super模式
supervisor:kernel mode
cpu被允许执行==特权指令==
举个例子,当一个应用程序尝试执行一条特殊权限指令,因为不允许在user mode执行特殊权限指令,处理器会拒绝执行这条指令。通常来说,这时会将控制权限从user mode切换到kernel mode,当操作系统拿到控制权之后,或许会杀掉进程,因为应用程序执行了不该执行的指令
运行在内核空间(或者说super模式)的软件称呼为内核;
usermode
只能运行普通权限的指令。
usermode->kernelmode
补充内容:用户程序会通过系统调用来切换到kernel mode。当用户程序执行系统调用,会通过ECALL触发一个软中断(software interrupt),软中断会查询操作系统预先设定的中断向量表,并执行中断向量表中包含的中断处理程序。中断处理程序在内核中,这样就完成了user mode到kernel mode的切换,并执行用户程序想要执行的特殊权限指令。
我们可以认为user/kernel mode是分隔用户空间和内核空间的边界,用户空间运行的程序运行在user mode,内核空间的程序运行在kernel mode。操作系统位于内核空间。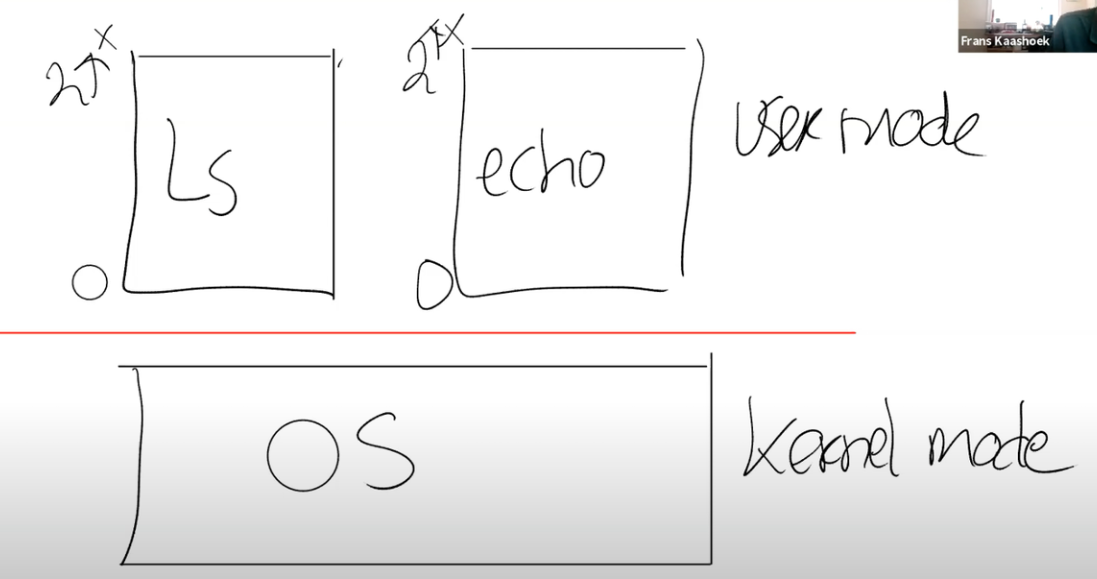
ecall :唯一也是专门的指令,能够让应用程序将控制权交给内核
当一个用户程序想要将程序执行的控制权转移到内核,它只需要执行ECALL指令,并传入一个数字。这里的数字参数代表了应用程序想要调用的System Call。
ECALL会跳转到内核中一个特定,由内核控制的位置。在XV6中存在一个唯一的系统调用接入点,每一次应用程序执行ECALL指令,应用程序都会通过这个接入点进入到内核中。举个例子,不论是Shell还是其他的应用程序,当它在用户空间执行fork时,它并不是直接调用操作系统中对应的函数,而是调用ECALL指令,并将fork对应的数字作为参数传给ECALL。之后再通过ECALL跳转到内核。
下图中通过一根竖线来区分用户空间和内核空间,左边是用户空间,右边是内核空间。在内核侧,有一个位于syscall.c的函数syscall,每一个从应用程序发起的系统调用都会调用到这个syscall函数,syscall函数会检查ECALL的参数,通过这个参数内核可以知道需要调用的是fork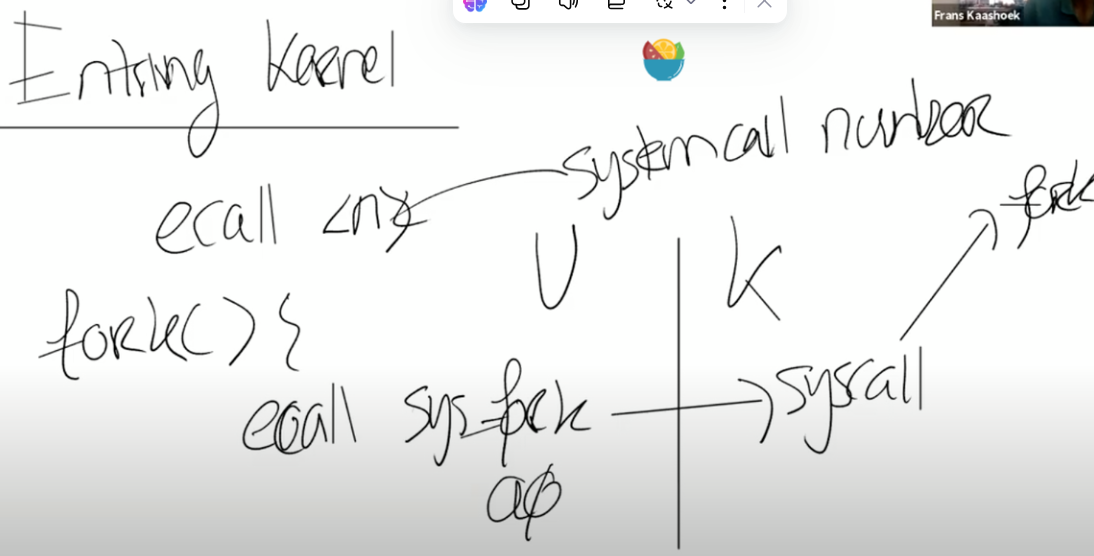
页表page table(这里往下是虚拟内存)
xv6使用页表为每个进程提供了自己的地址空间,risc-v页表将虚拟地址转换成物理地址;
进程的用户空间内存地址是从虚拟地址0开始的,
存放顺序:指令-》全局变量-》栈-》堆区(malloc)
内核
TCB:可被信任的计算空间(Trusted Computing Base
- 要被称为TCB,内核首先要是正确且没有Bug的。假设内核中有Bug,攻击者可能会利用那个Bug,并将这个Bug转变成漏洞,这个漏洞使得攻击者可以打破操作系统的隔离性并接管内核。所以内核真的是需要越少的Bug越好(但是谁不是呢)。
- 另一方面,内核必须要将用户应用程序或者进程当做是恶意的。内核的设计人员在编写和实现内核代码时,必须要有安全的思想。这个目标很难实现,因为当你的操作系统变得足够大的时候,很多事情就不是那么直观了。几乎每一个你用过的或者被广泛使用的操作系统,时不时的都有一个安全漏洞。就算被修复了,但是过了一段时间,又会出现一个新的漏洞。我们之后会介绍为什么很难让所有部分都正确工作,但是你要知道是内核需要做一些tricky的工作,需要操纵硬件,需要非常小心做检查,所以很容易就出现一些小的疏漏,进而触发一个Bug。这也是可以理解的。
宏内核
整个操作系统代码都运行在kernel mode。大多数的Unix操作系统实现都运行在kernel mode。比如,XV6中,所有的操作系统服务都在kernel mode中,这种形式被称为Monolithic Kernel Design。所有系统调用的实现都在super模式下进行;
特点
- 代码居多,从安全的角度来说,在内核中有大量的代码是宏内核的缺点。
- 宏内核的优势在于,因为这些子模块现在都位于同一个程序中,它们可以紧密的集成在一起,这样的集成提供很好的性能。例如Linux,它就有很不错的性能。

微内核
减少内核中的代码,它被称为Micro Kernel Design。在这种模式下,希望在kernel mode中运行尽可能少的代码。所以这种设计下还是有内核,但是内核只有非常少的几个模块。在用户模式下执行操作系统的大部分代码。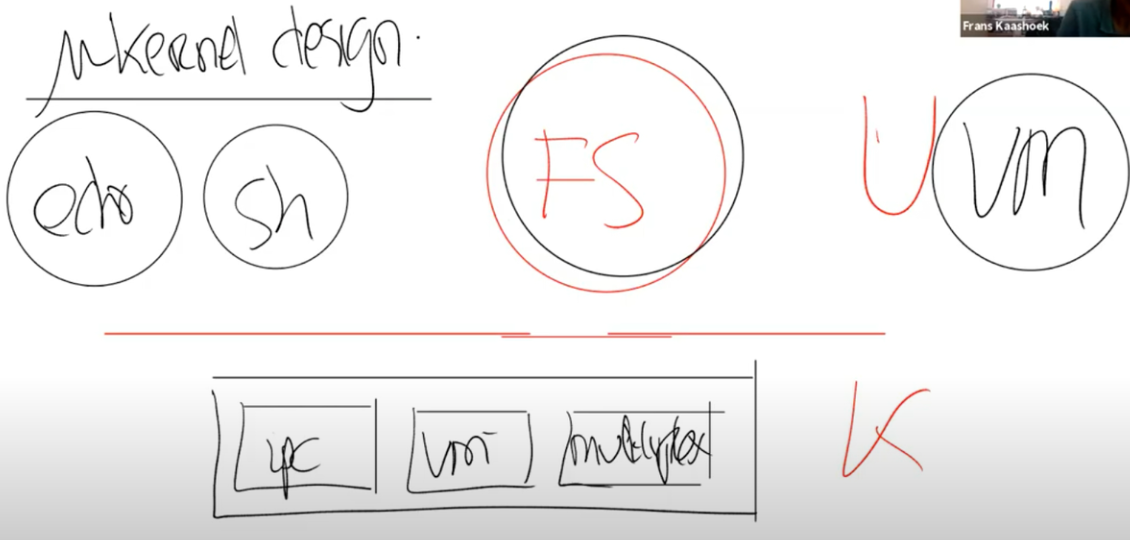
但是在和内核的交互中存在一点问题:
比如Shell调用了exec,必须有种方式可以接入到文件系统中。通常来说,这里工作的方式是,Shell会通过内核中的IPC系统发送一条消息,内核会查看这条消息并发现这是给文件系统的消息,之后内核会把消息发送给文件系统。文件系统会完成它的工作之后会向IPC系统发送回一条消息说,这是你的exec系统调用的结果,之后IPC系统再将这条消息发送给Shell
通过消息实现系统调用,是宏内核跳转的两倍
特点
- 在内核中的代码的数量较小,更少的代码意味着更少的Bug。
- 在user/kernel mode反复跳转带来的性能损耗。
- 在一个类似宏内核的紧耦合系统,各个组成部分,例如文件系统和虚拟内存系统,可以很容易的共享page cache。而在微内核中,每个部分之间都很好的隔离开了,这种共享更难实现。进而导致更难在微内核中得到更高的性能。
xv6内核
模块间的接口在kernel/defs.h被定义
代码介绍
kernel
里面包含了基本上所有的内核文件。因为XV6是一个宏内核结构,这里所有的文件会被编译成一个叫做kernel的二进制文件,然后这个二进制文件会被运行在kernle mode中。
user
基本上是运行在user mode的程序。这也是为什么一个目录称为kernel,另一个目录称为user的原因。
mkfs
它会创建一个空的文件镜像,我们会将这个镜像存在磁盘上,这样我们就可以直接使用一个空的文件系统
内核编译
Makefile会为所有内核文件做相同的操作,比如说pipe.c,会按照同样的套路,先经过gcc编译成pipe.s,再通过汇编解释器生成pipe.o。
之后,系统加载器(Loader)会收集所有的.o文件,将它们链接在一起,并生成内核文件。
这里生成的内核文件就是我们将会在QEMU中运行的文件。同时,为了你们的方便,Makefile还会创建kernel.asm,这里包含了内核的完整汇编语言,你们可以通过查看它来定位究竟是哪个指令导致了Bug。
qemu
当你想到QEMU时,你不应该认为它是一个C程序,你应该把它想成是下图,一个真正的主板。
process overview
隔离单位,进程抽象,为程序提供一种整个机器是它自己私有的错觉,私有的cpu,只有自己执行指令等;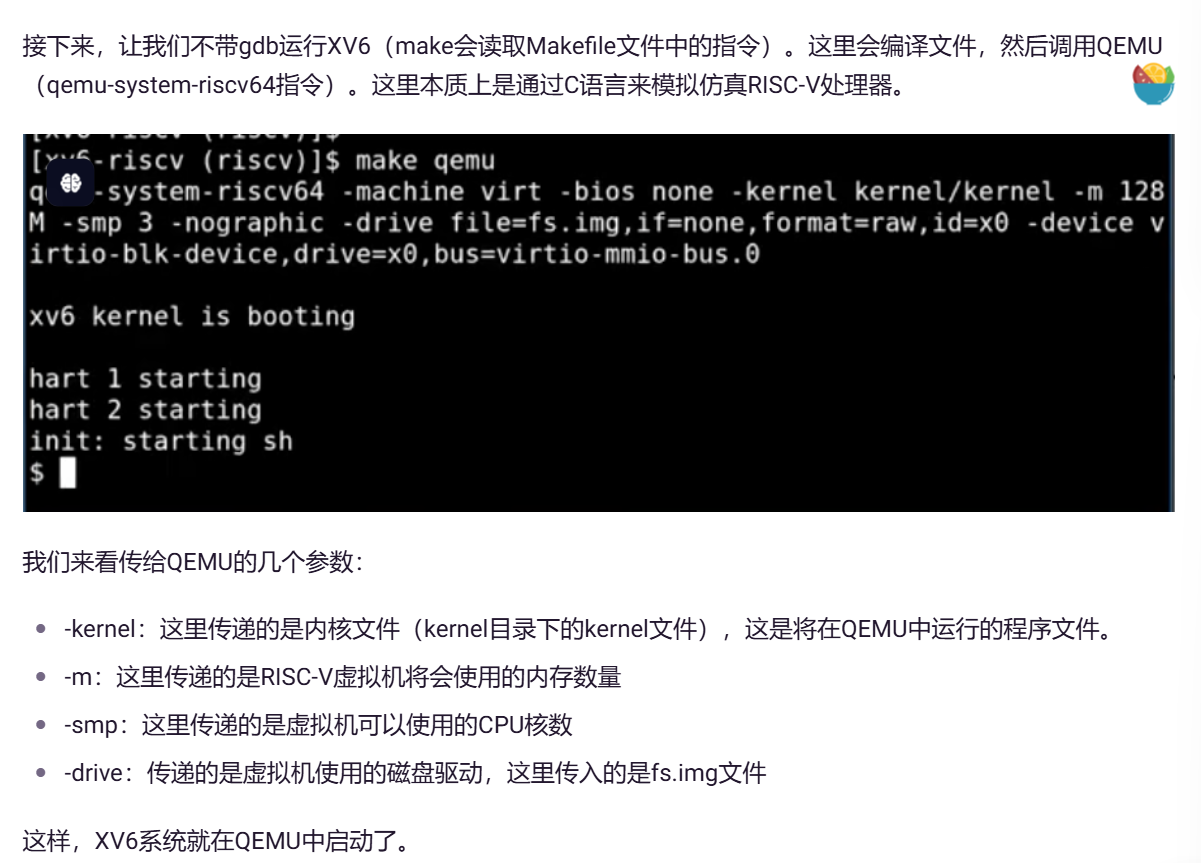
proc结构体
存放了很多内核状态:页表,内核栈,运行状态;
用p->xxx 表示Proc结构的元素
线程
每一个进程都会有一个执行线程;如果在进程之间进行透明的切换,内存会暂停当前运行的线程,然后恢复另一个进程的线程;
线程的大部分状态存储在线程的栈中;
每个进程有两个栈:用户栈,内核栈;
进程的线程在用户栈和内核栈中交替执行。
进程的线程可以在内核中阻塞等待i/o。等待i/o完成后,再从离开的地方恢复。


启动和运行第一个进程
????看不太懂
lecture 6
Traps and system calls
有三种时间会导致cpu搁置普通指令的执行
[!PDF|] XV6-Chinese-2020, p.32
有三种事件会导致 CPU 搁置普通指令的执行,强制将控制权转移给处理该事件的特殊代码。一种情况是系统调用,当用户程序执行 ecall 指令要求内核为其做某事时。另一种情况是异常:一条指令(用户或内核)做了一些非法的事情,如除以零或使用无效的虚拟地址。第三种情况是设备中断,当一个设备发出需要注意的信号时,例如当磁盘硬件完成一个读写请求时。
系统调用 ecall
异常
设备中断
我们希望被中断的代码意识不到trap,通常的顺序是
[!PDF|yellow] XV6-Chinese-2020, p.33trap 迫使控制权转移到内核;内核保存寄存器和其他状态,以便恢复执行;内核执行适当的处理程序代码(例如,系统调用实现或设备驱动程序);内核恢复保存的状态,并从 trap 中返回;代码从原来的地方恢复。
Xv6 trap处理的四个阶段
补充 调度



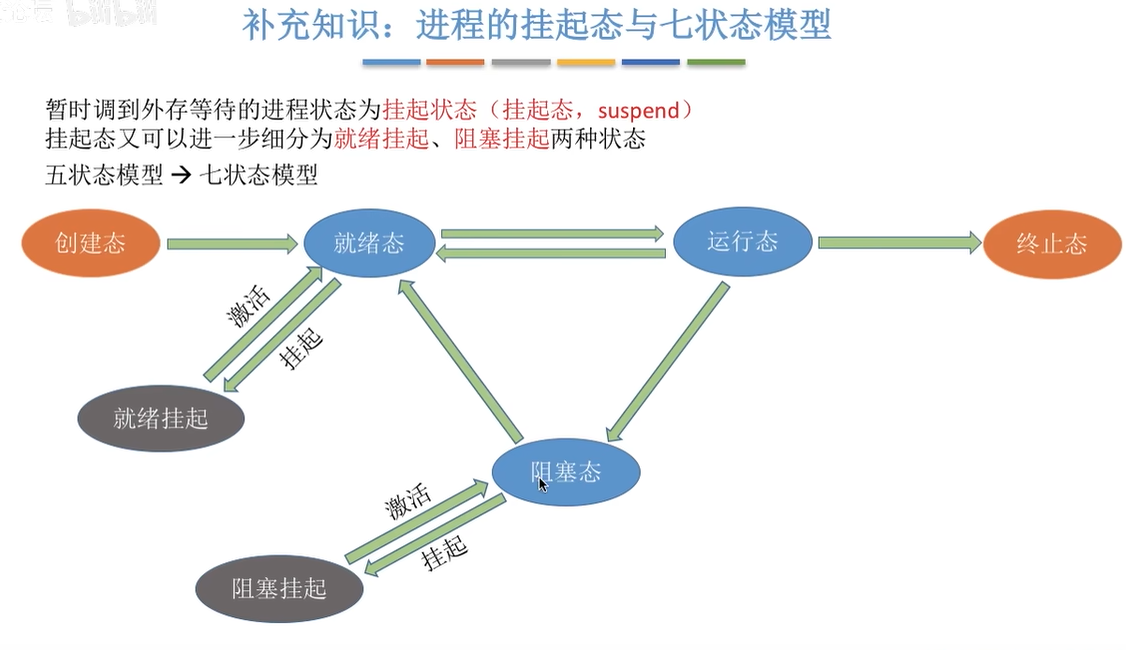
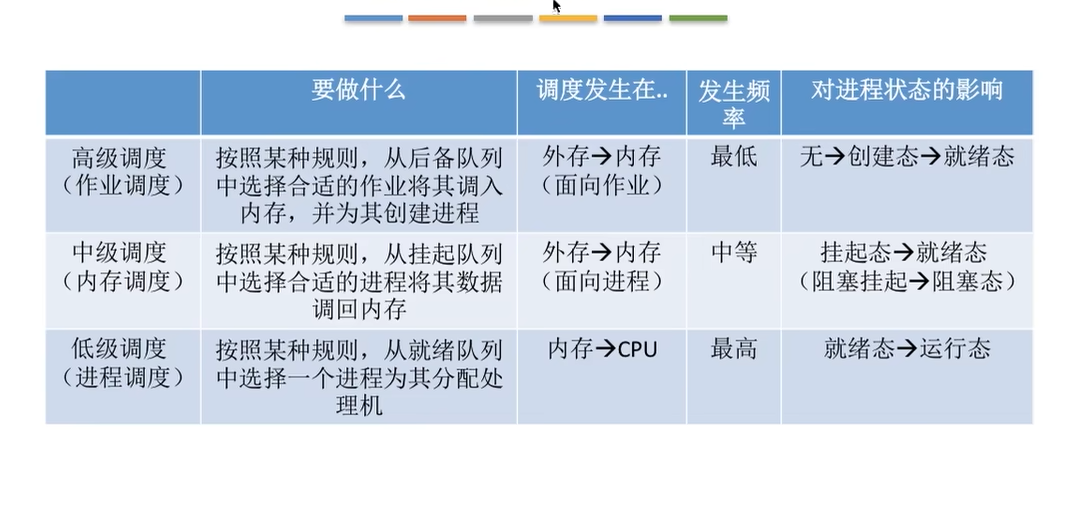
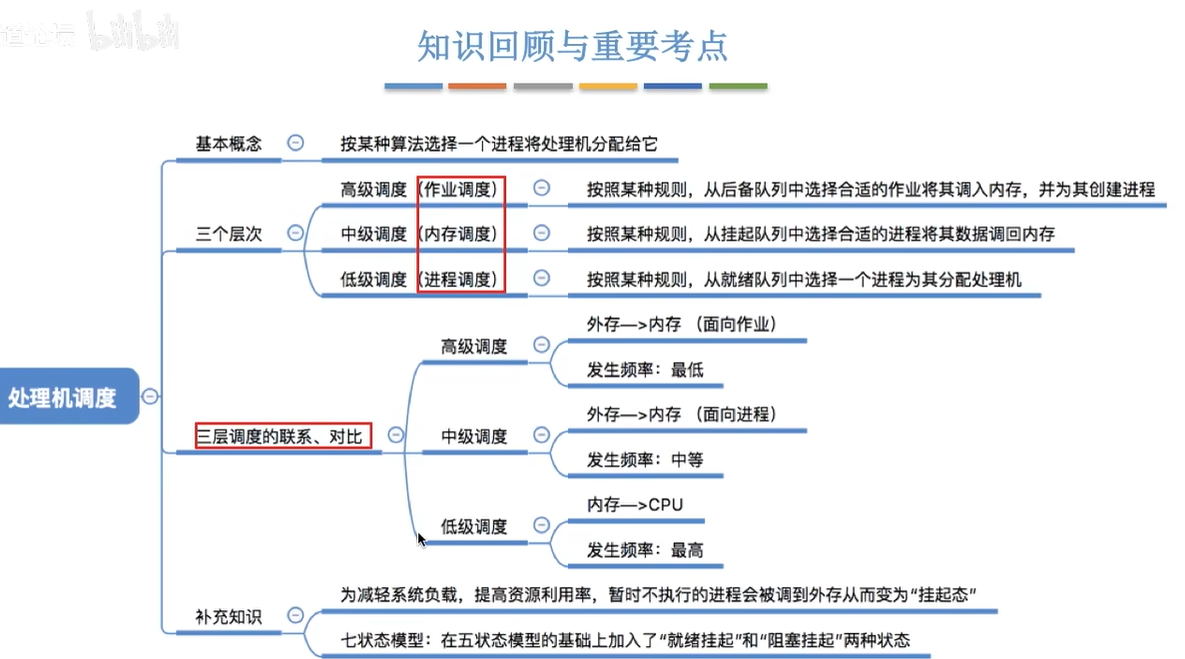
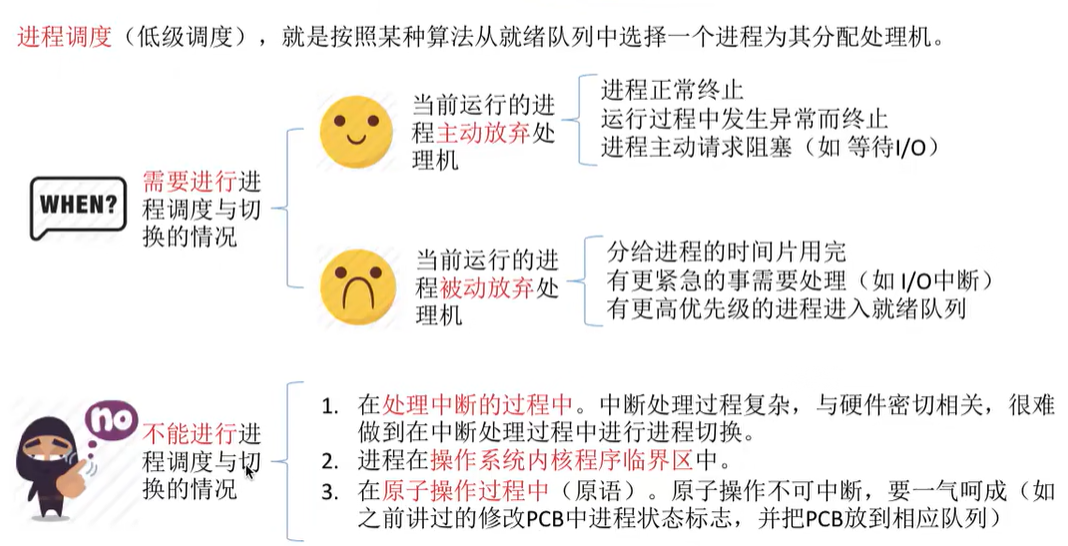
进程调度的时机
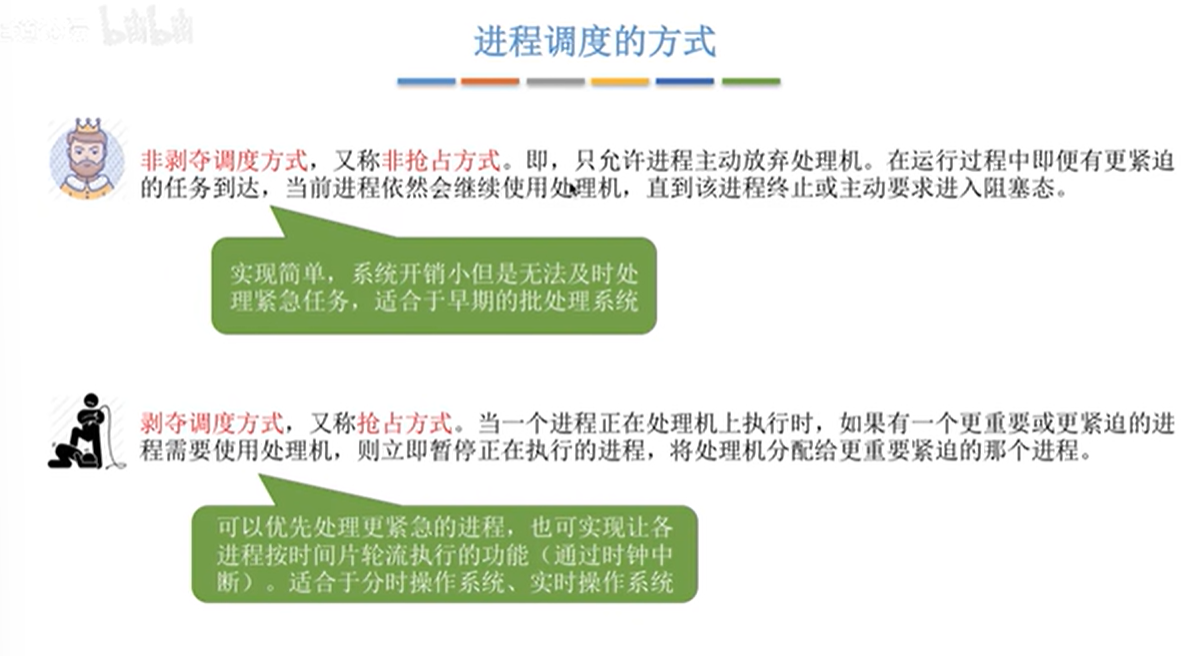
进程调度的方式
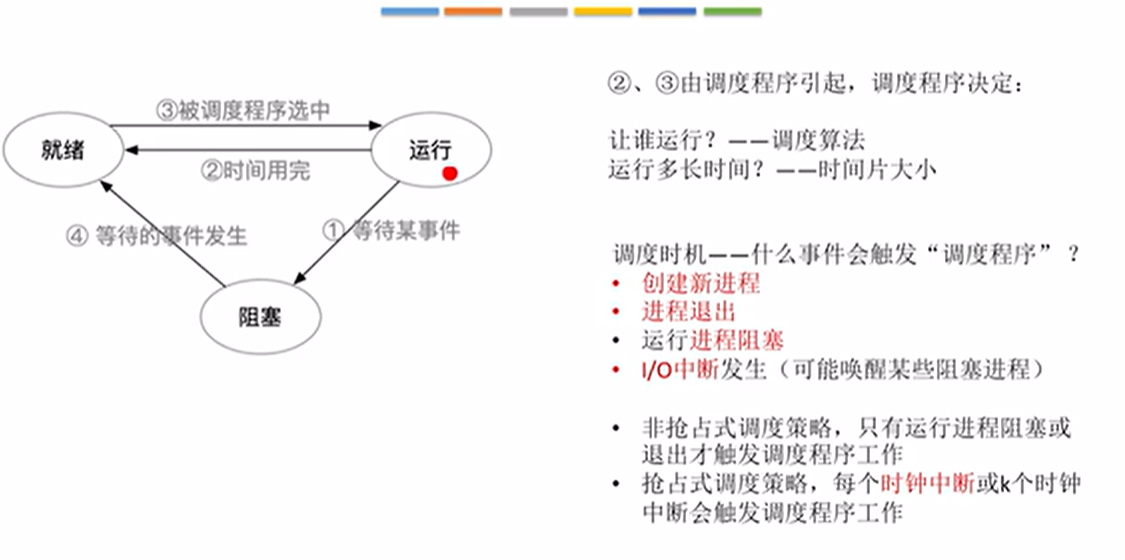
闲逛进程

进程调度
FIFO FCFS 先来先服务

SJF 最短任务优先 STCF 最短完成时间优先

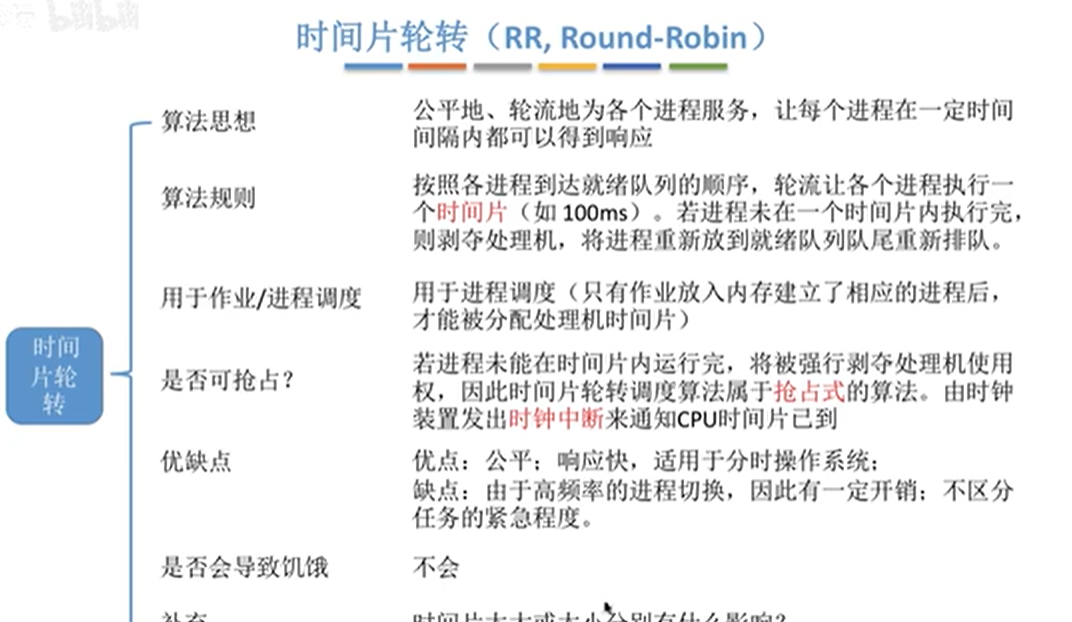
RR 时间片轮转
MLFQ 多级反馈队列

link