深度学习
PyTorch 教程 | 菜鸟教程
PyTorch 文档 — PyTorch 2.6 文档 - PyTorch 深度学习库
NumPy 教程 | 菜鸟教程
简介 - Python教程 - 廖雪峰的官方网站
https://www.runoob.com/pandas/pandas-tutorial.html
配置环境

预备知识
python
- hashlib :哈希算法,对任意长度的数据data计算出固定长度的哈希digest,对数据进行加密
- slice 创建一个切片对象,用于访问数组切片,常用于k则交叉验证
1 | |
- python 类
- super(type[, object-or-type]) super() 函数是用于调用父类(超类)的一个方法。
- Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
- 比较运算符is z.cuda(0) is z 比较是否是同一个对象
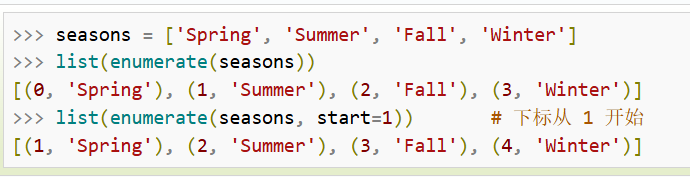
- zip 返回一个迭代器对象
- isinstance 比较一个对象是否是已知的类型
- enumerate 将索引和数据对象(列表,元组,字符串)组成一个序列
- (i,对象)
pandas
pytorch
- torch.clamp 配合神经网络一起用,稳定预测值

- 按照指定维度连接张量

- torch.rand

- torch.randn

- torch.zeros

- torch.matmul

- torch.ones

- X.T

- nn.Conv2d

- torch.stack

- torch.normal torch.normal(mean, std, size) 生成size形状的正态分布张量
- torch.arange

- torch.numel

训练的数据迭代操作(常用)
torchvision
- transforms.Resize(resize) 调整图片大小
numpy
数据操作
1 | |
soft回归(分类)
图像数据集的获取
TIPS:
zip(),将数组打包成配对的元组
shuzu.flatten() 将多维数组展平成一维数组
enumerate(zip(axes, imgs)) → 迭代器包含 [(0, (ax1, img1)), (1, (ax2, img2)), (2, (ax3, img3))]
soft回归的简单实现
o=x w +b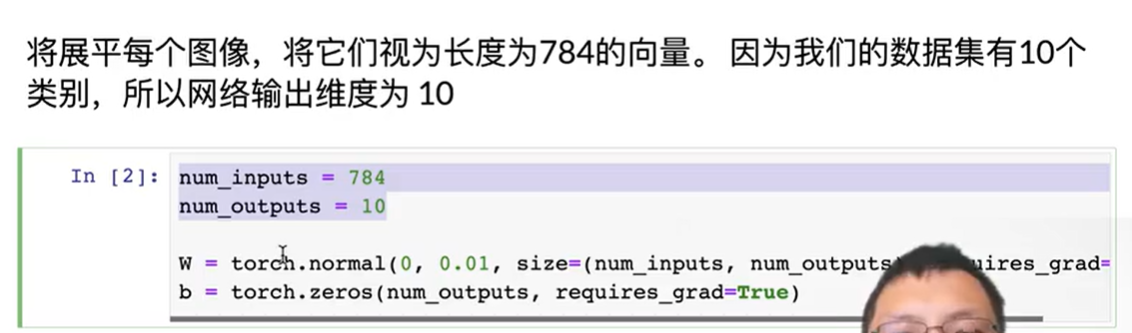 w初值 行数=输入的个数,列数=输出的个数
w初值 行数=输入的个数,列数=输出的个数
问题
- 输入数据X的形状(batch_sizse,1,28,28) 28* 28=784 batchsize个数据图形
w的形状:输入数据x展平后的形状784,输出类型10
展平:x.shape(-1,w.shape[0]) , batch_size个784向量的数据图形?
例如,如果原始X的形状是(32, 1, 28, 28)(即批次大小32,通道数1,图像尺寸28x28),那么X.reshape((-1, 784))会将每个图像展平为784维的向量,结果形状变为(32, 784),其中784就是W.shape[0],即输入特征数。 - y_hat=y_hat=
定义softmax操作
1.对每个项求幂exp
2.对每一行求和,得到规范化常数
3.将每一行除以其规范化参数,确保每行的和为1
正如上述代码,对于任何随机输入,[我们将每个元素变成一个非负数。 此外,依据概率原理,每行总和为1]。
定义模型

权重w将构成一个784×10的矩阵, 偏置b将构成一个1×10的行向量。
将数据传递到模型之前,我们使用reshape函数将每张原始图像展平为向量。
O = X w +B //X的形状变成256 (batch_size) *784
y预测值=softmax(O)
X一个样本 的数据结构
- 形状:通常为
(batch_size, height, width, channels)的四维张量(例如图像数据),但经过reshape后会被展平为(batch_size, input_features)。 - 内容:一个批量的样本数据,例如:
- 对于 Fashion-MNIST 数据集,每个样本是
28x28的灰度图,原始形状为(1, 28, 28)(通道数=1)。 - 经过
X.reshape((-1, W.shape[0]))操作后,每个图像被展平为长度784(即28 * 28)的一维向量,形状变为(batch_size, 784)。
- 对于 Fashion-MNIST 数据集,每个样本是
定义损失函数
交叉熵采用真实标签的预测概率的负对数似然。 这里我们不使用Python的for循环迭代预测(这往往是低效的), 而是通过一个运算符选择所有元素。
y_hat为y中对应标签在三个类型中的预测概率

交叉熵损失函数

下面,我们[**创建一个数据样本y_hat,其中包含2个样本在3个类别的预测概率, 以及它们对应的标签y。] 有了y,我们知道在第一个样本中,第一类是正确的预测; 而在第二个样本中,第三类是正确的预测。 然后(使用y作为y_hat中概率的索引), 我们选择第一个样本中第一个类的概率和第二个样本中第三个类的概率。
分类精度
当预测与标签分类y一致时,即是正确的。
分类精度即正确预测数量与总预测数量之比,精度通常是我们最关心的性能衡量标准
逻辑:
- 那么假定第二个维度存储每个类的预测分数。 我们使用
argmax获得每行中最大元素的索引来获得预测类别。 - 然后我们[将预测类别与真实
y元素进行比较]。 由于等式运算符“==”对数据类型很敏感, 因此我们将y_hat的数据类型转换为与y的数据类型一致。 结果是一个包含0(错)和1(对)的张量 - 最后,我们求和会得到正确预测的数量。

评估给定模型net和给定数据集的精度
- 定义实用程序类Accumulator,用于对多个变量进行累加。
- !
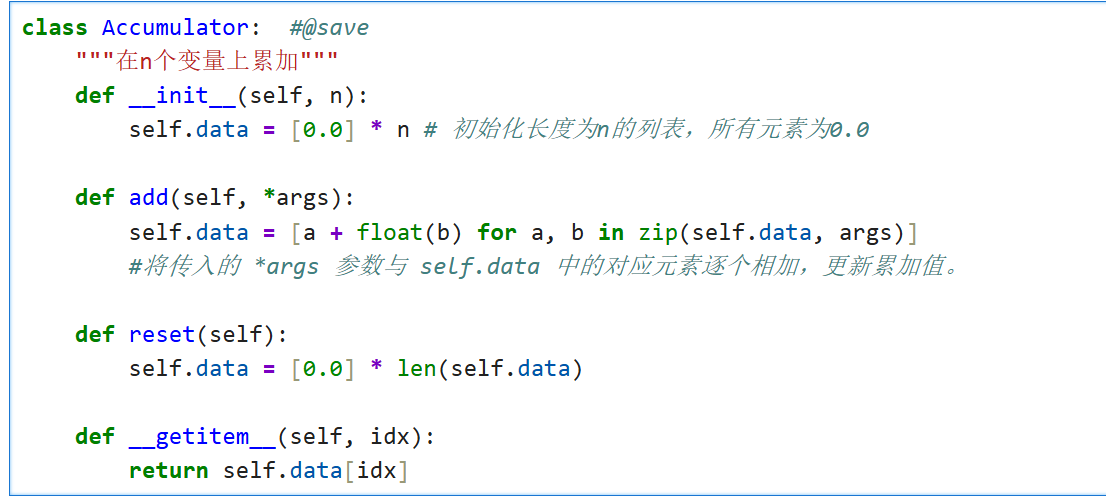
- 计算在指定数据集上模型的精度

训练
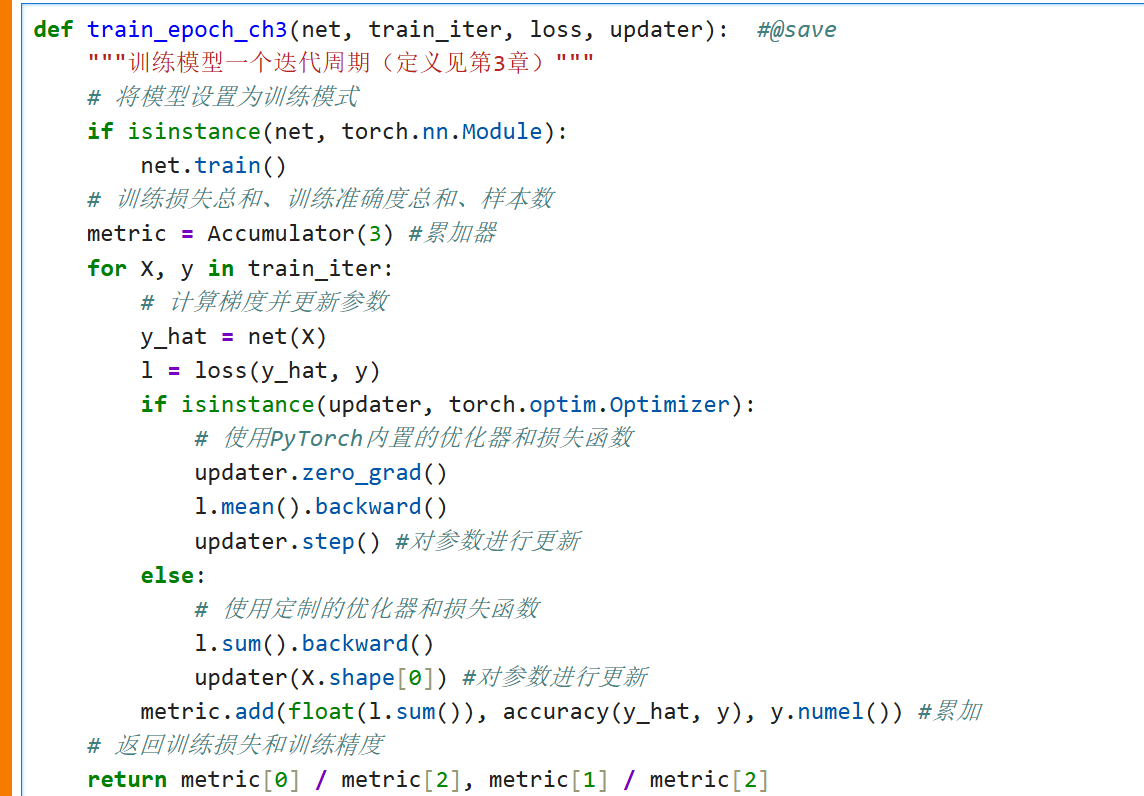
小批量随机梯度下降来优化模型的损失函数
updater


soft回归的简洁实现
初始化模型参数

softmax回归的输出层是一个全连接层
定义顺序模型net,包含Flatten层和Linear层
Flatten把输入展平->linear进行矩阵乘法
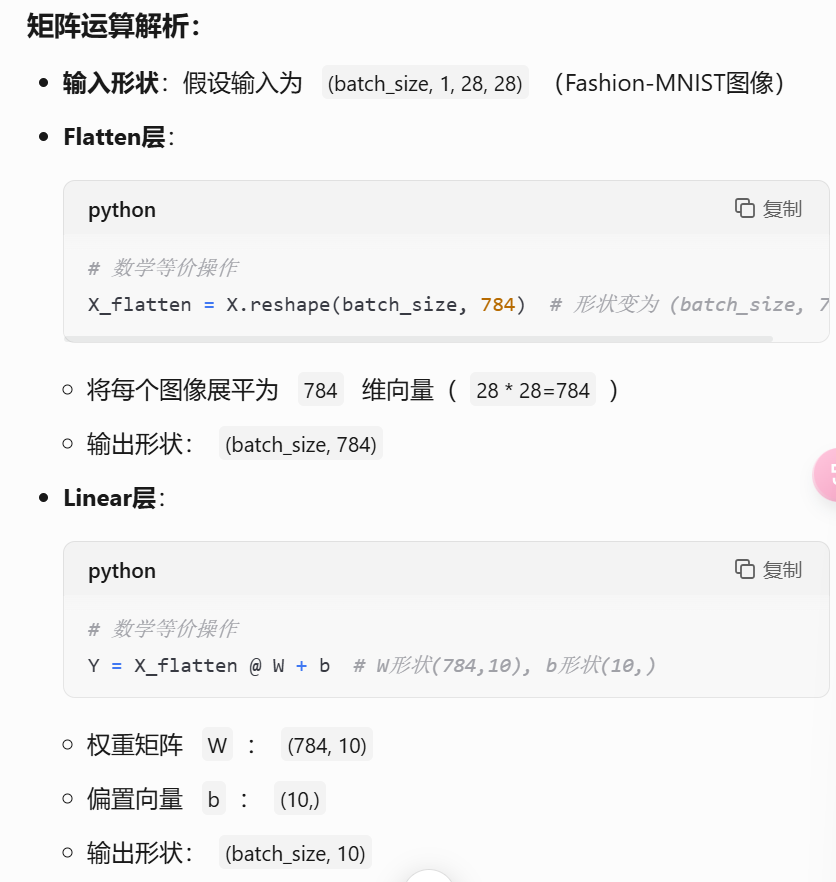
损失函数计算和优化算法

训练

重新审视softmax的实现

然而这可能会导致下溢,所以我们避免计算以下: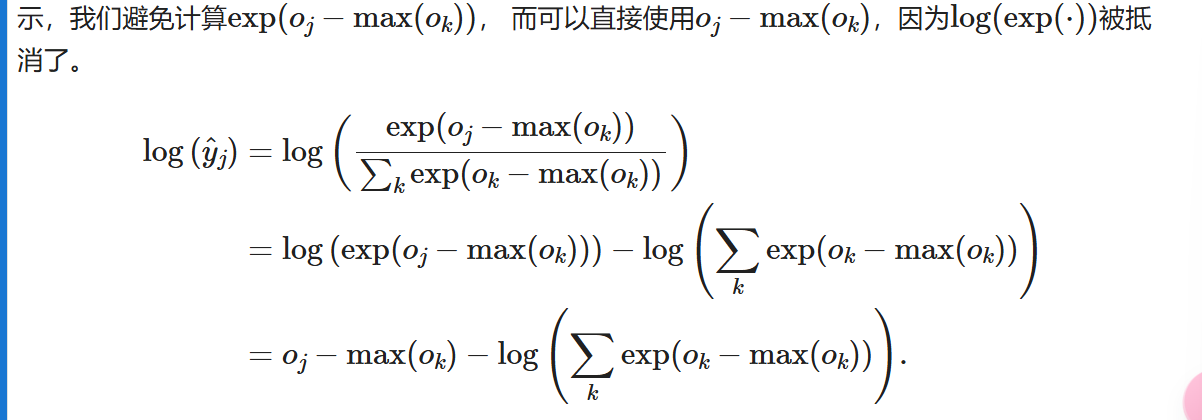 [在交叉熵损失函数中传递未规范化的预测,并同时计算softmax及其对数], 这是一种类似“LogSumExp技巧”的聪明方式。
[在交叉熵损失函数中传递未规范化的预测,并同时计算softmax及其对数], 这是一种类似“LogSumExp技巧”的聪明方式。
多层感知机
为什么需要感知机:
线性模型可能会出错:单调假设,没有考虑一些特殊情况,线性不一定合理,
有很多违背单调性的例子:比如37摄氏度下应该以人的体温与37度的距离进行比较
在网络中加入隐藏层克服线性模型的限制
MLP(多层感知机)
感知机是什么

$\mathbf{X} \in \mathbb{R}^{n \times d}$表示$n$个样本的小批量,每个样本具有$d$个输入特征
$\mathbf{H} \in \mathbb{R}^{n \times h}$表示隐藏层的输出,成为隐藏表示,用对隐藏单元应用非线性的激活函数
$\mathbf{O} \in \mathbb{R}^{n \times q}$:表示输出O
激活函数的输出(例如,$\sigma(\cdot)$)被称为活性值(activations)。
一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型:
$$
\begin{aligned}
\mathbf{H} & = \sigma(\mathbf{X} \mathbf{W}^{(1)} + \mathbf{b}^{(1)}), \
\mathbf{O} & = \mathbf{H}\mathbf{W}^{(2)} + \mathbf{b}^{(2)}.\
\end{aligned}
$$
损失函数
下面的$y_i$指的是给该层输出分的类(-1或1),<w,x>+b指的是经过输出函数处理前的输出:
如果y=-1且wx+b>=0,分类错误
如果y=1且wx+b<=0,
直到所有预测的分类都正确,y*<w,x> >0
l<y,x,w> = max(0,-y<w,x>) 如果分类正确,返回0;如果分类错误,有梯度进行更新
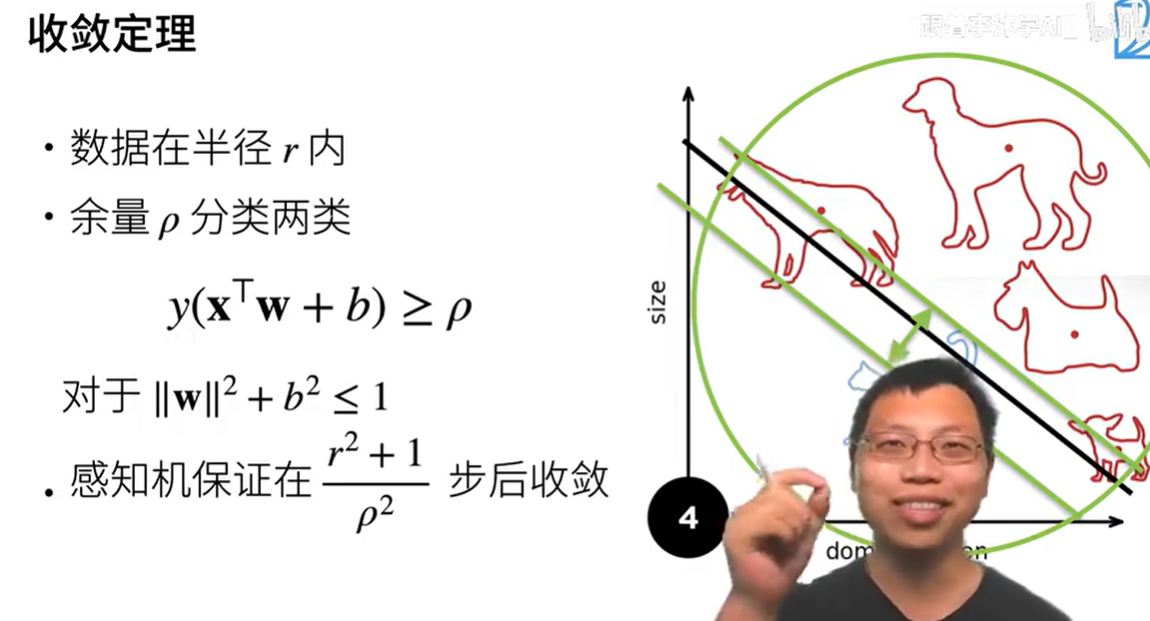
感知机对函数面进行分割,直到找到最优解(收敛定理为止)
收敛定理
最优解什么时候停止更新,以下公式成立时收敛
$y(x^{T}w+b) \geq p$
r为数据的大小,p为余量
XOR问题
感知机的分割为一条线,没法分割如图情况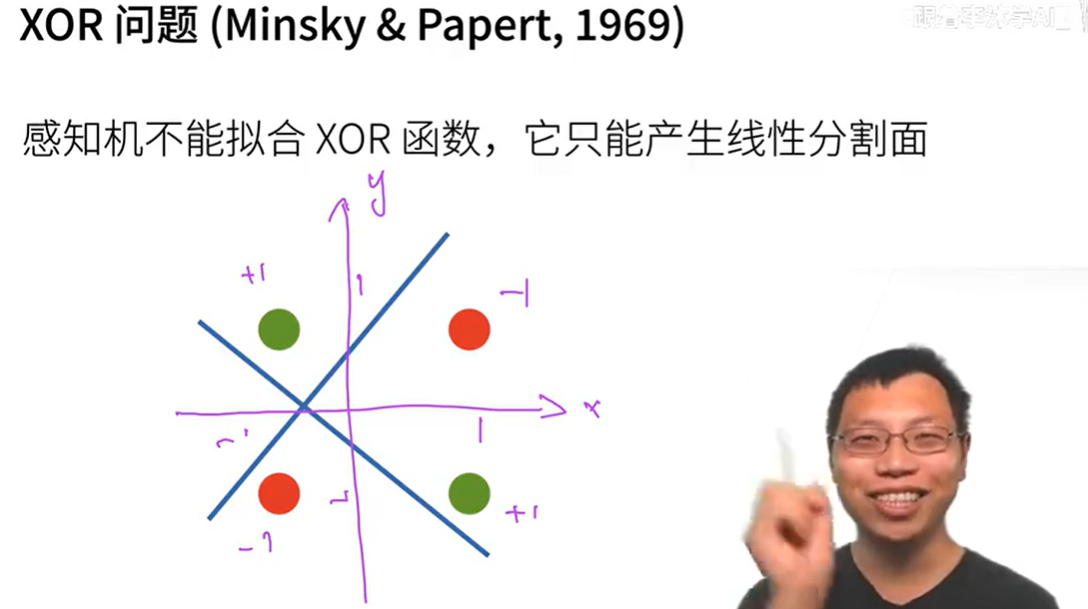
学习XOR
对面上的不同物体进行多次分类后异或得出结果,蓝线为第一次分类,黄线为第二次分类,product后得出最终结果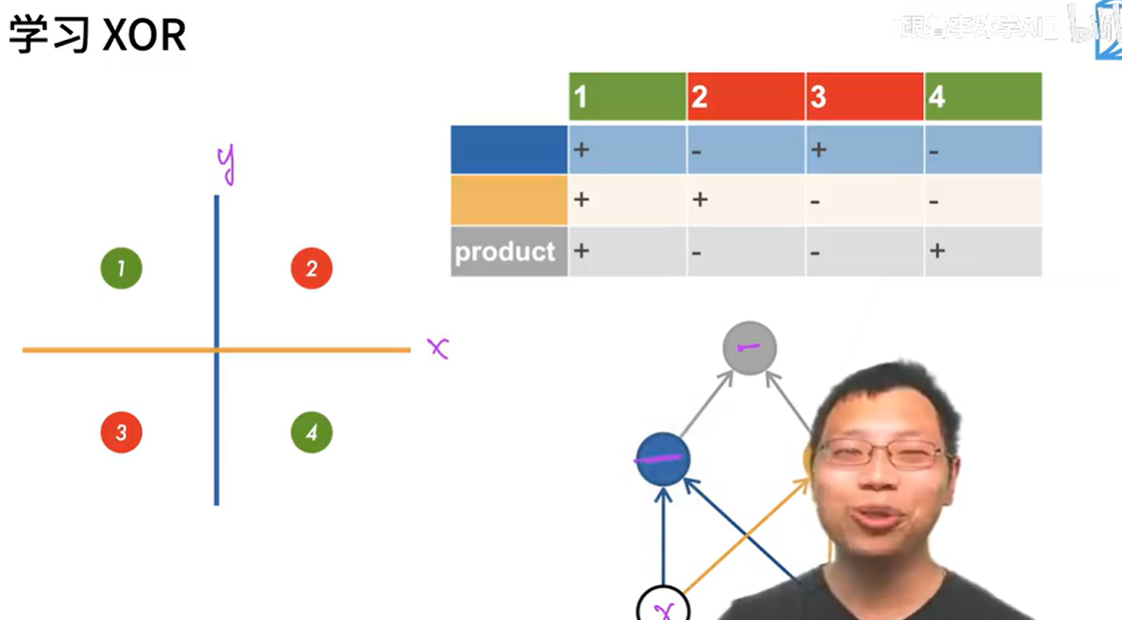
多层感知机
超参数 :隐藏层大小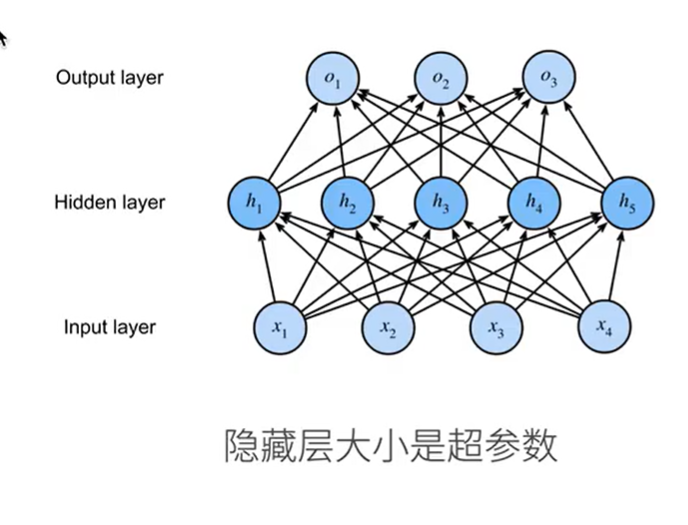
单分类
X输入n个样本
W1 m为隐藏层的大小,n为输入大小
B1 为偏移量,有多少个隐藏层就有多少偏移
输出层 w2 ,隐藏层为m个,输出m * 1(单分类)
h作为输入进输出层,o输出为标量
形状变化:
输入:X[n,1]
隐藏层:H[m,1]=W[m,n]X[n1] +b[m,1]
输出层:w2[1,m]* H[m,1]=O[1,1] //标量
问题:只输出一个标量嘛?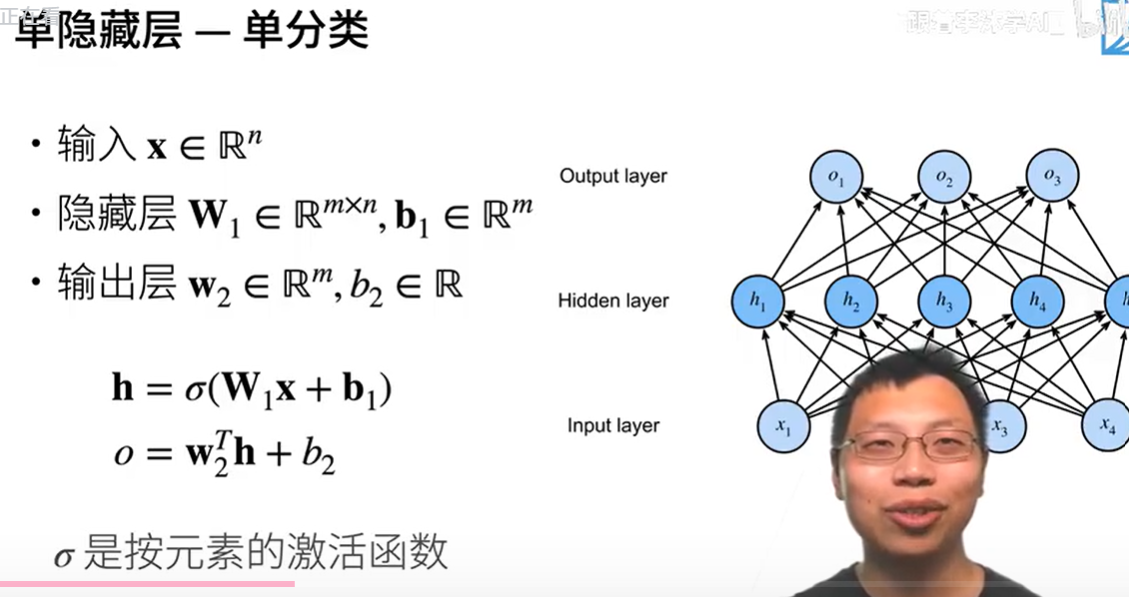
激活函数
Sigmoid激活函数
一个有软衔接的1,0函数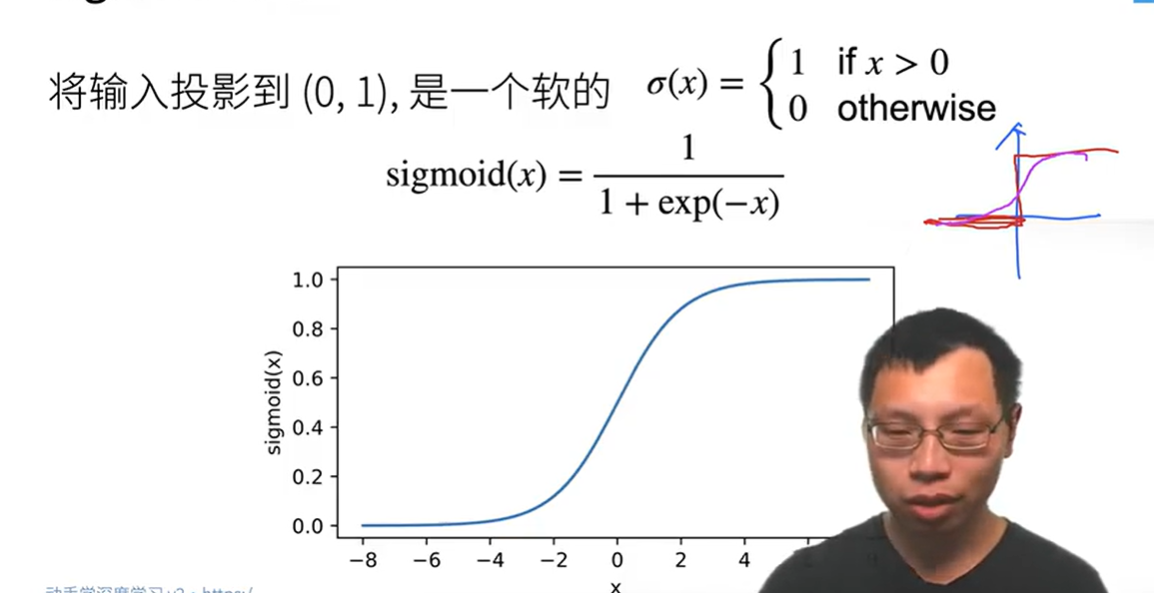
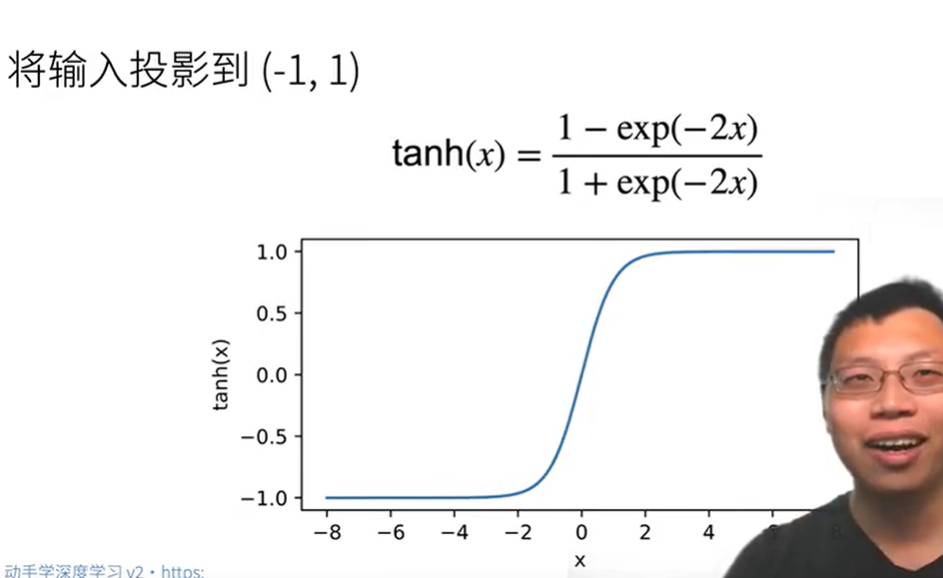
Tanh激活函数
ReLU激活函数
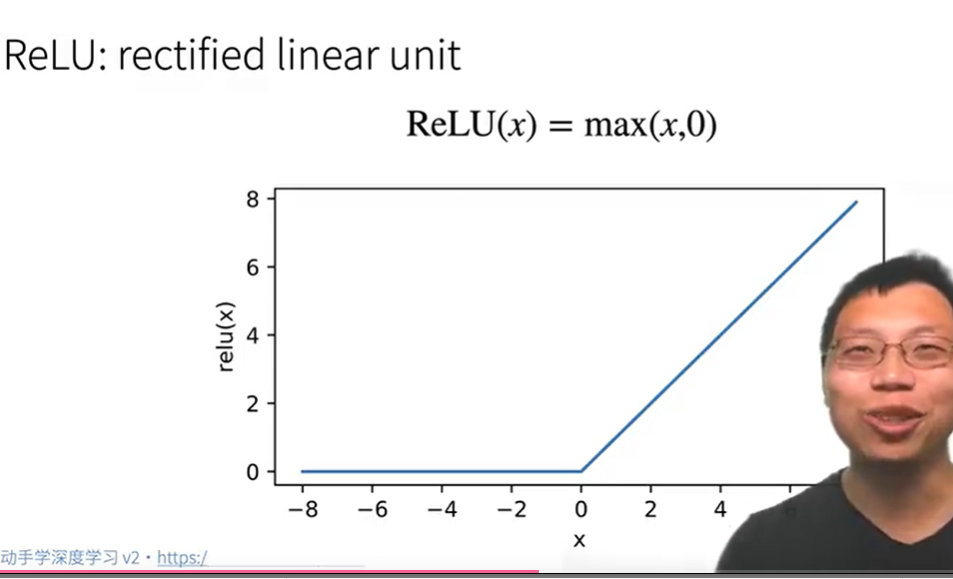
指数运算很贵,Relu可以避免指数运算
多分类
将输入的X(n个输入特征)->输出[n(n个样本),m(m个分类对于的概率)]
相当于在softmax回归里加入一层隐藏层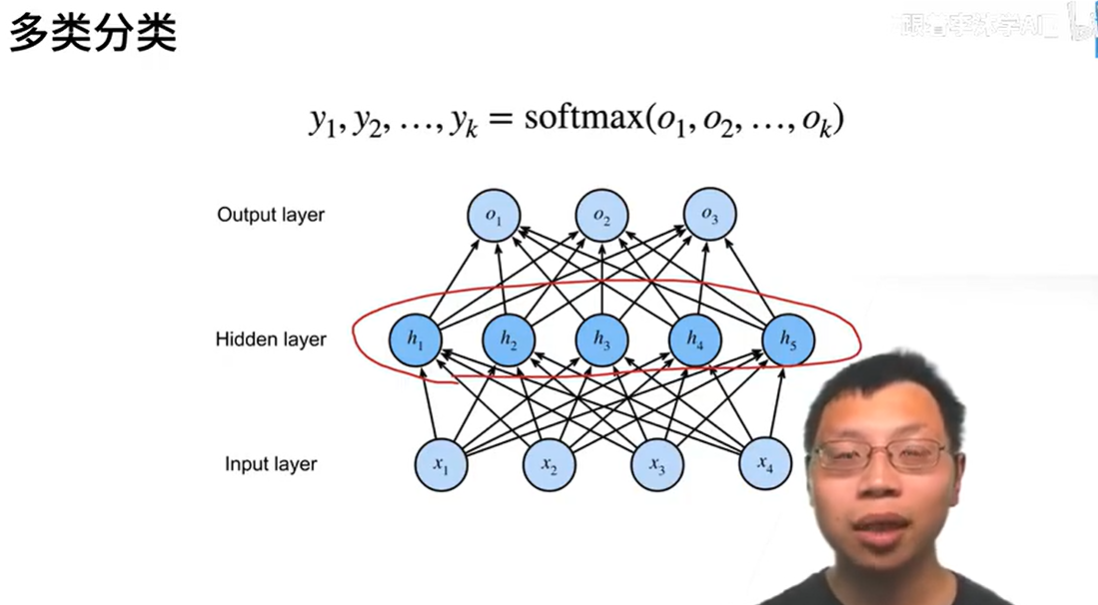

输入x[n,1](n个输入特征)
隐藏层W1[m,n]* X[n,1] +B[m,1]
输出层(由1变成k,k个分类) :H[m,1]=激励函数(W1[m,n]* X[n,1] +B[m,1])
O[k,1]=W2[k,m]* H[m,1] +b[k,1]
y[k,1] =softmax(o)
多隐藏层
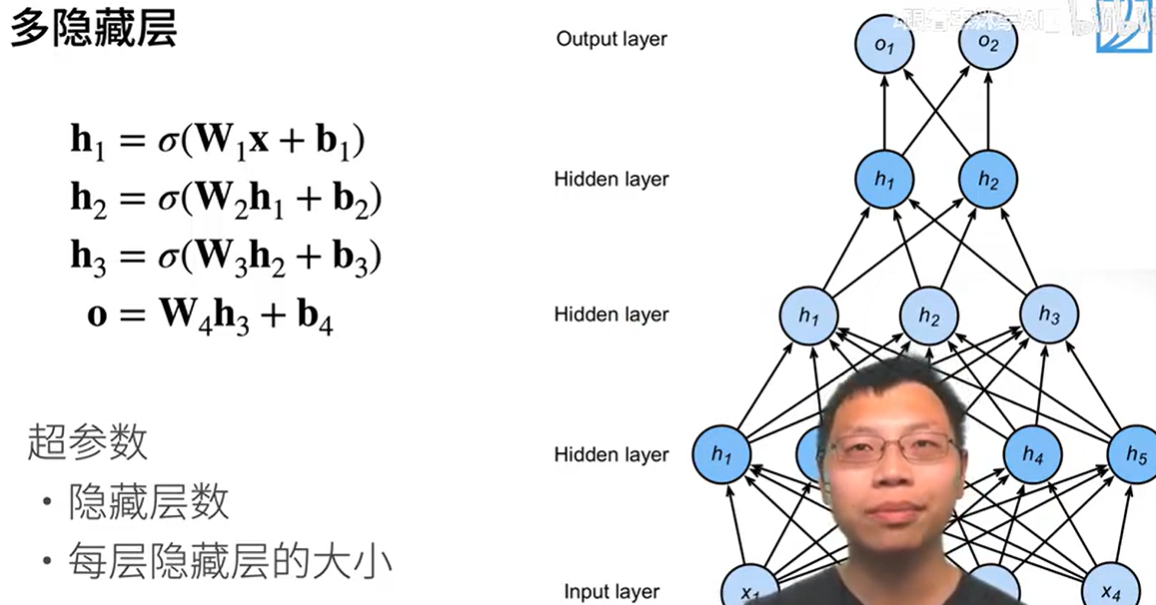
上一隐藏层的输出为下一隐藏层的输入
超参数 隐藏层的层数,每层隐藏层的大小
- 金字塔结构:隐藏层大小逐层递减(如
[512, 256, 128]),慢慢压缩输入,从512->256->128 - 等宽网络:所有隐藏层大小相同(如
[256, 256, 256]),简化超参数搜索。 - 宽度 vs 深度:
- 增加宽度(单层神经元数)更适合学习宽泛特征。
- 增加深度(更多隐藏层)更适合层次化特征。
多层感知机的从零开始实现
初始化模型参数
num_inputs=28*28=784 输入的图片有784个像素
num_outputs=10 10个分类
num_hiddens=256 单隐藏层的大小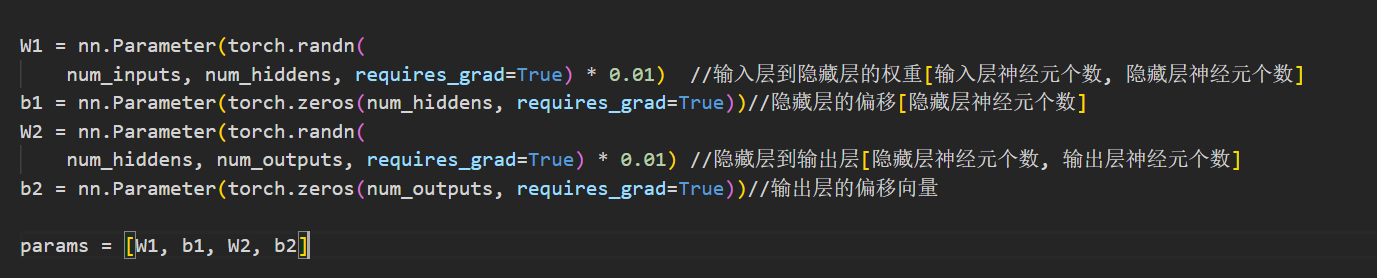
激活函数
relu激活函数实现原理:将所有的负值变为0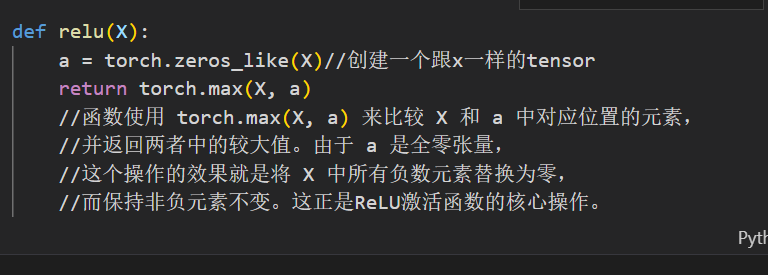
模型
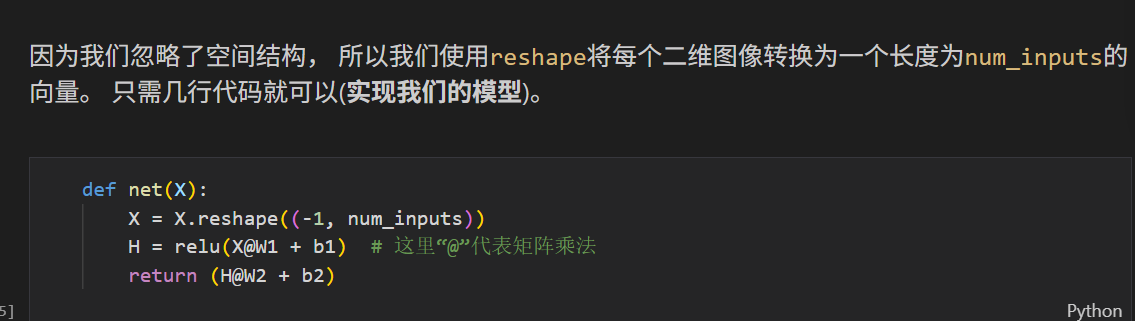
损失函数
交叉熵损失
训练

答疑
一层网络指的是可学习的权重,w为[头节点数量*尾节点数量],对应两层节点之间的箭头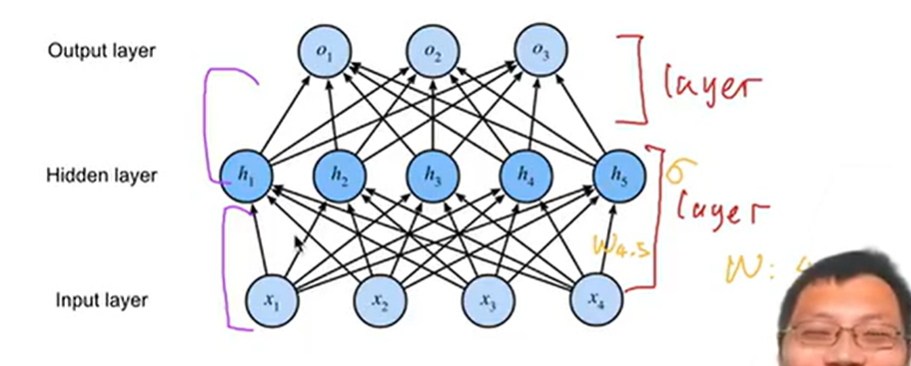
模型选择,过拟合和欠拟合
训练误差和泛化误差 实际中一般靠观察
- 训练误差:模型在训练数据集上计算得到的误差
- 泛化误差:模型在新数据上的误差(模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,模型误差的期望)
泛化误差只能用独立的测试集来估计泛化误差 - 验证数据集:选择模型超参数,用来评估模型好坏的数据集(测试超参数的好坏,不参与训练,不要和训练数据混在一起)
- 测试数据集:只用一次的数据集
一般把数据分成三份,训练,测试,验证
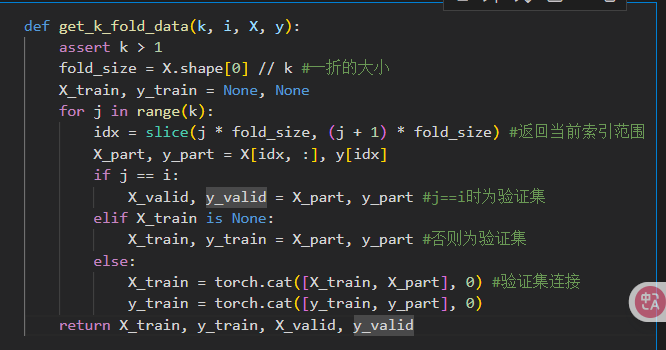
k-则交叉验证 数据太少怎么办
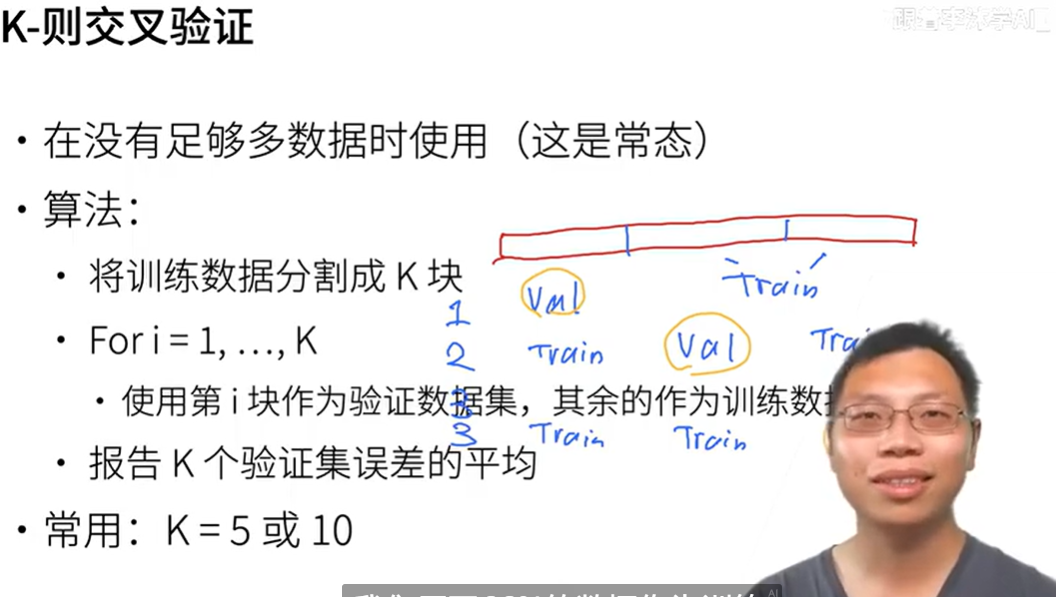
实现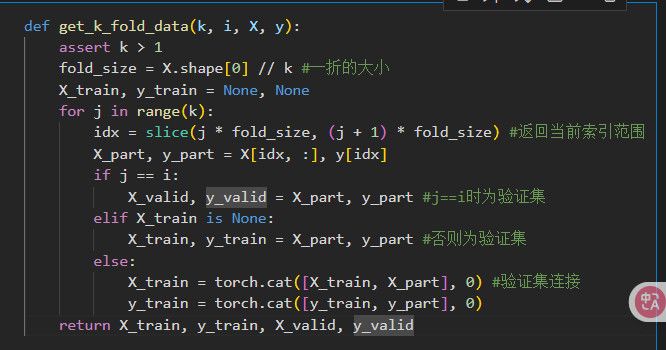
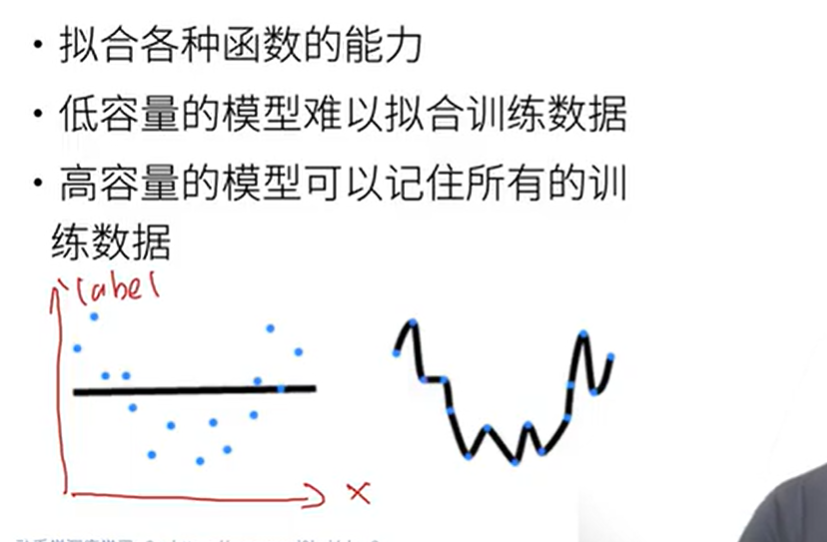
过拟合和欠拟合
数据和模型容量的选择

数据简单,模型容量高->过拟合,数据都被记住,没有很好的泛化性
数据复杂,模型容量低->欠拟合,模型简单,表达能力不足模型容量的概念
-
模型容量的影响
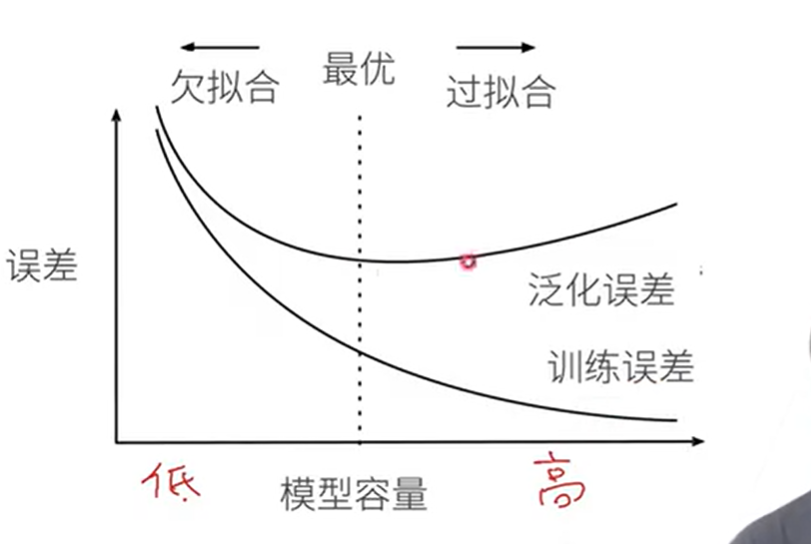
估计模型容量
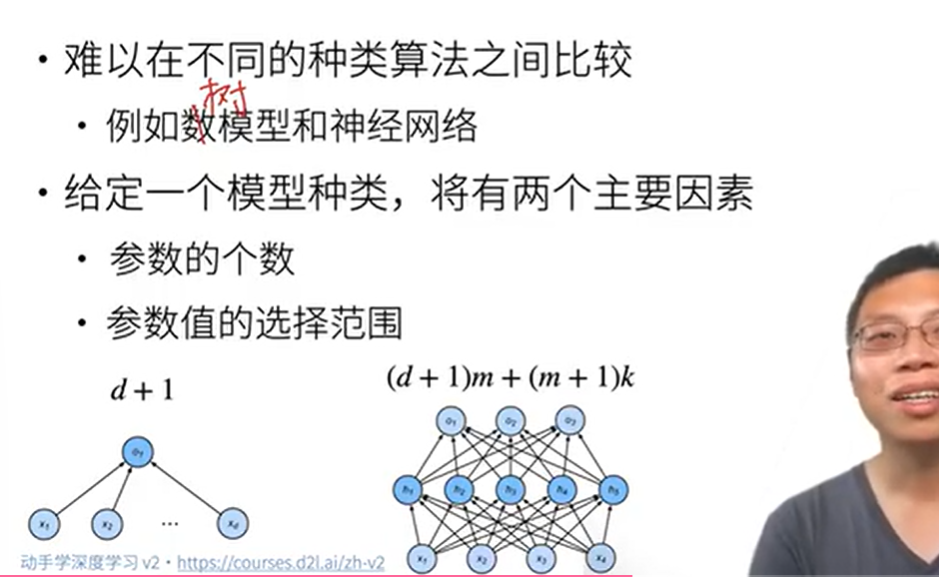
参数数量:公式
(d + 1)m + (m + 1)k- 输入层→隐藏层:
(d + 1)m(d输入特征维度,+1是偏置,m是隐藏层神经元数)。 - 隐藏层→输出层:
(m + 1)k(m输入维度,+1偏置,k输出维度)。 - 举例:输入特征维度
d=10,隐藏层m=20,输出k=2→ 参数总数(10+1)*20 + (20+1)*2 = 262。
- 输入层→隐藏层:
统计学的一些东西 知道就行
- VC维 深度学习很少用

例子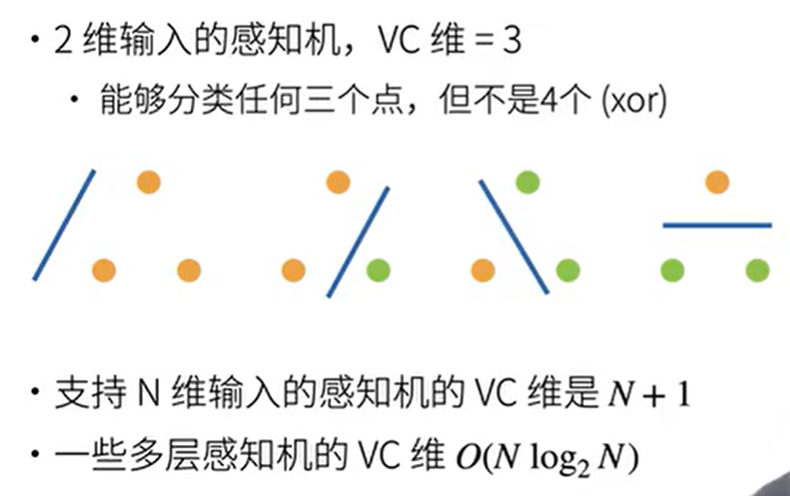
- 数据复杂度:样本个数,每个样本的元素个数,时空结构,多样性
权重衰减
缓解过拟合 通过L2正则项使得模型参数不会过大,从而控制模型复杂度,正则项权重是控制模型复杂度的$\lambda$超参数
使用均方范数作为硬性限制
通过限制参数值的选择范围来控制模型容量 有点太硬使用均方范数作为柔性限制

让我们回顾一下 :numref:sec_linear_regression中的线性回归例子。
我们的损失由下式给出:
$$L(\mathbf{w}, b) = \frac{1}{n}\sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2.$$
回想一下,$\mathbf{x}^{(i)}$是样本$i$的特征,$y^{(i)}$是样本$i$的标签,$(\mathbf{w}, b)$是权重和偏置参数。为了惩罚权重向量的大小,我们必须以某种方式在损失函数中添加$| \mathbf{w} |^2$,但是模型应该如何平衡这个新的额外惩罚的损失?实际上,我们通过正则化常数$\lambda$来描述这种权衡,这是一个非负超参数,我们使用验证数据拟合:
$$L(\mathbf{w}, b) + \frac{\lambda}{2} |\mathbf{w}|^2,$$
对于$\lambda = 0$,我们恢复了原来的损失函数。
对于$\lambda > 0$,我们限制$| \mathbf{w} |$的大小。
这里我们仍然除以$2$:当我们取一个二次函数的导数时,$2$和$1/2$会抵消,以确保更新表达式看起来既漂亮又简单。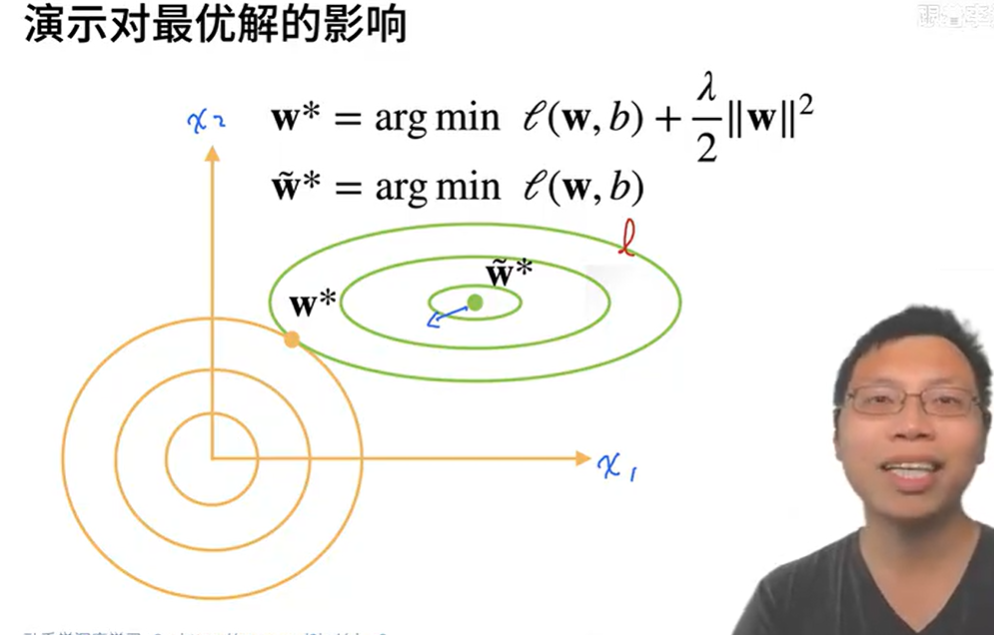
- 参数更新法则

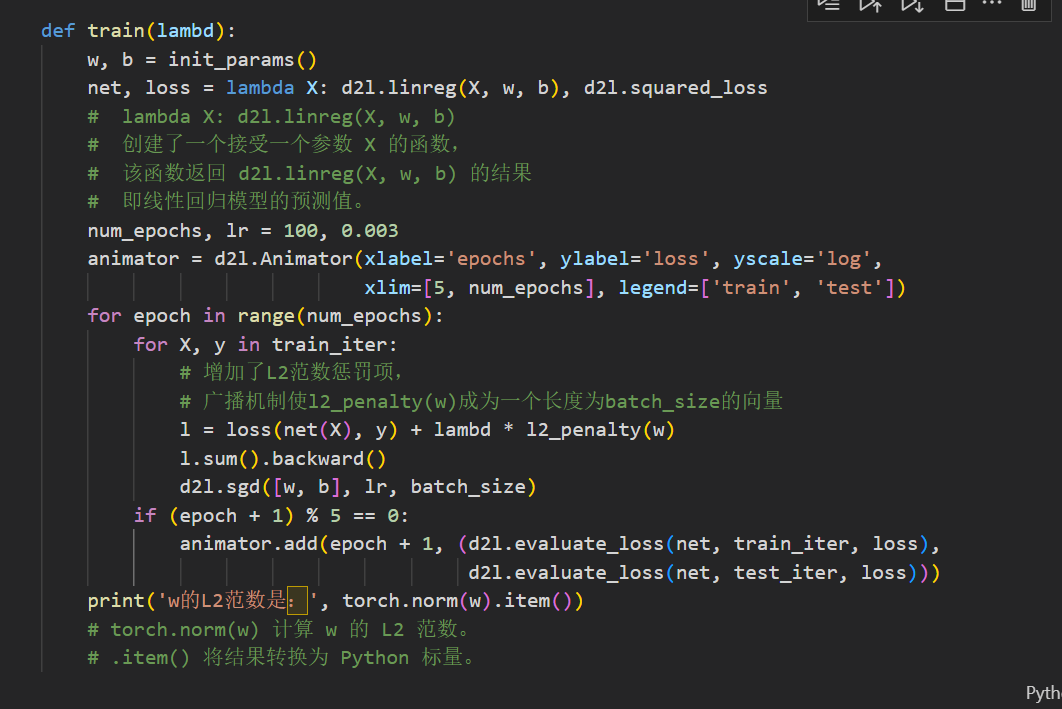
从0代码实现
- 初始化模型参数

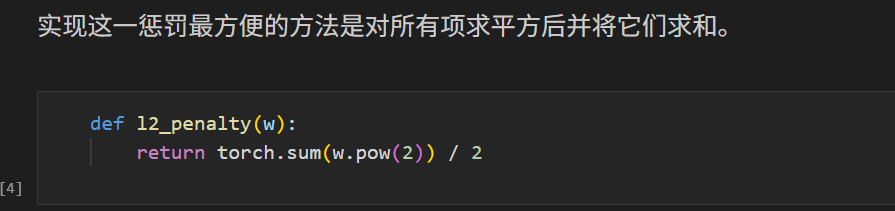
- 定义L2范数惩罚
- 训练代码实现(lambd为正则化权重超参数)
简洁实现
深度学习框架将权重衰减集成到优化算法中,便于任何损失函数结合使用
在下面的代码中,我们在实例化优化器时直接通过weight_decay指定weight decay超参数。
默认情况下,PyTorch同时衰减权重和偏移。
这里我们只为权重设置了weight_decay,所以偏置参数$b$不会衰减。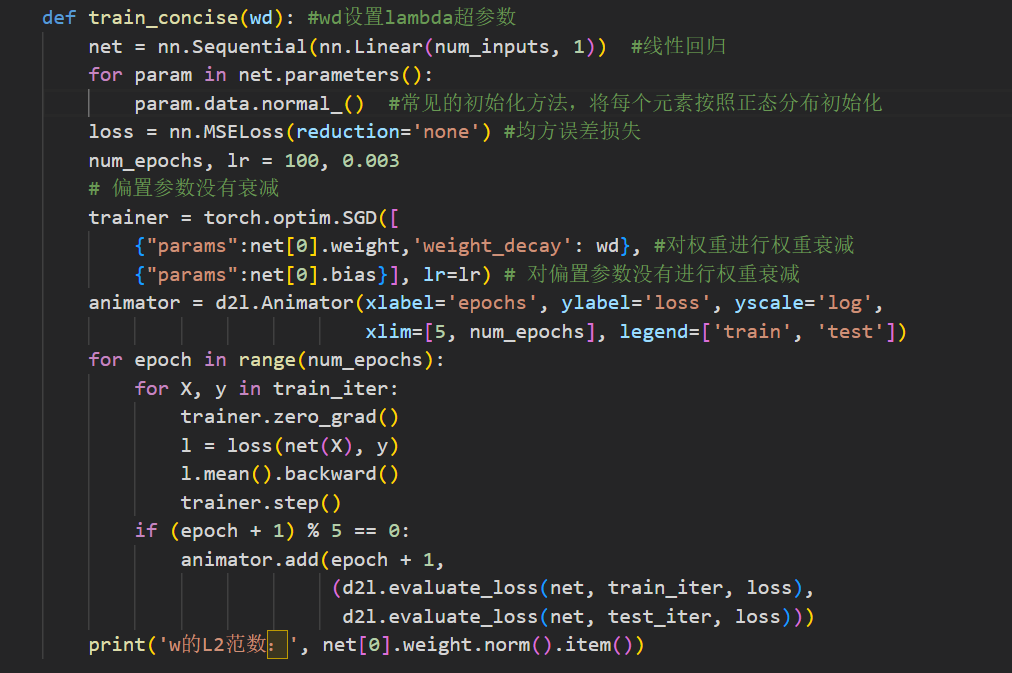
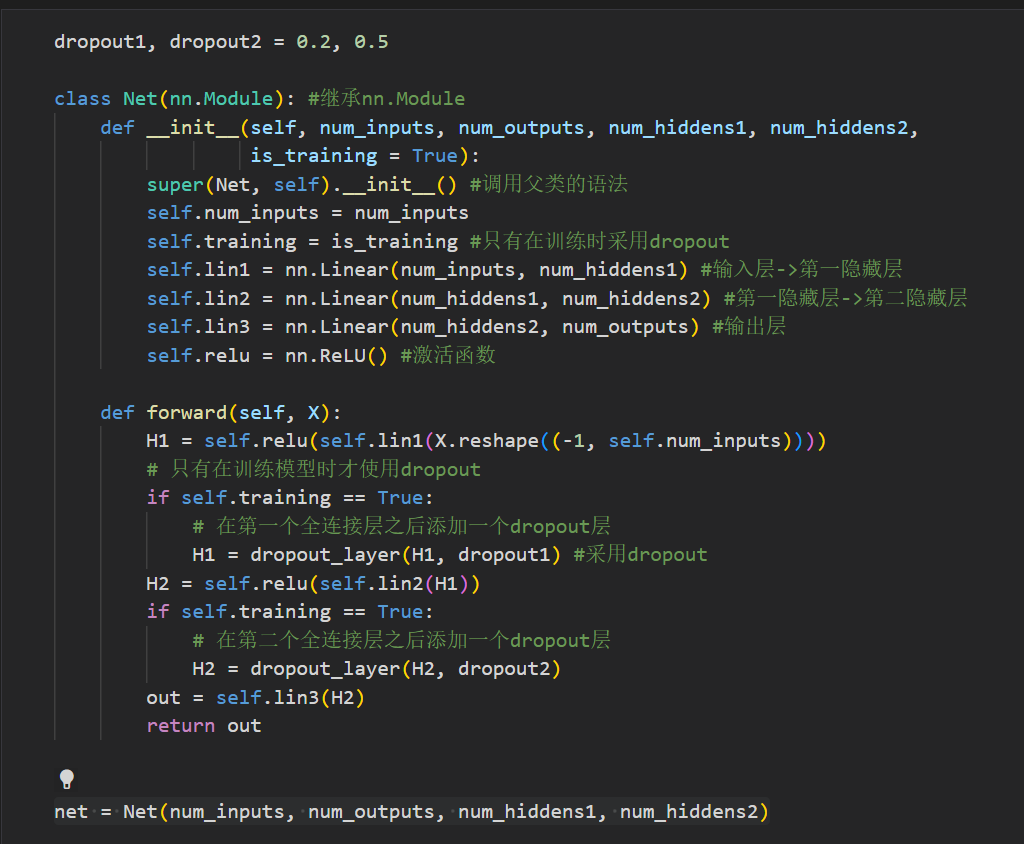
丢弃法(dropout)
将一些输出项随机置0来控制模型复杂度
常用于多层感知机的隐藏层输出上
丢弃概率$p$是控制模型复杂度的超参数
暂退法:只在训练期间有效
动机
- 无论加入多少噪音,都能有一个比较好的输出(比如图片有很多噪点,但是可以看清楚这个图片)
- 函数不应该对微小的输入变化敏感。
- 正则:使得权重不要太大,避免一定的过拟合

丢弃法:在前向传播过程中,计算每一内部层的同时注入噪声
无偏差的加入噪音:
- 希望在每一层的期望值等于没有噪音的值 E[x’]=x
- 对每个元素进行以下扰动$$
\begin{aligned}
x’ =
\begin{cases}
0 & \text{ 概率为 } p \
\frac{x}{1-p} & \text{ 其他情况}
\end{cases}
\end{aligned}
$$
使用丢弃法:
- 对第一个隐藏层的输出h作用dropout变为h’
- 输出为o = W h’ + b
- y = softmax(o)
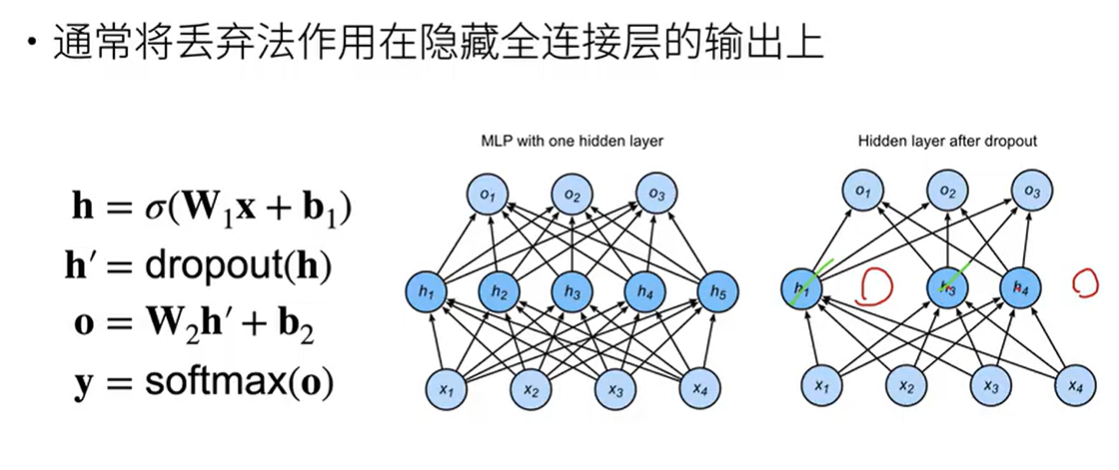
回想一下 :numref:fig_mlp中带有1个隐藏层和5个隐藏单元的多层感知机。
当我们将暂退法应用到隐藏层,以$p$的概率将隐藏单元置为零时,
结果可以看作一个只包含原始神经元子集的网络。
比如在 :numref:fig_dropout2中,删除了$h_2$和$h_5$,
因此输出的计算不再依赖于$h_2$或$h_5$,并且它们各自的梯度在执行反向传播时也会消失。
这样,输出层的计算不能过度依赖于$h_1, \ldots, h_5$的任何一个元素。
推理过程的丢弃法

从0代码
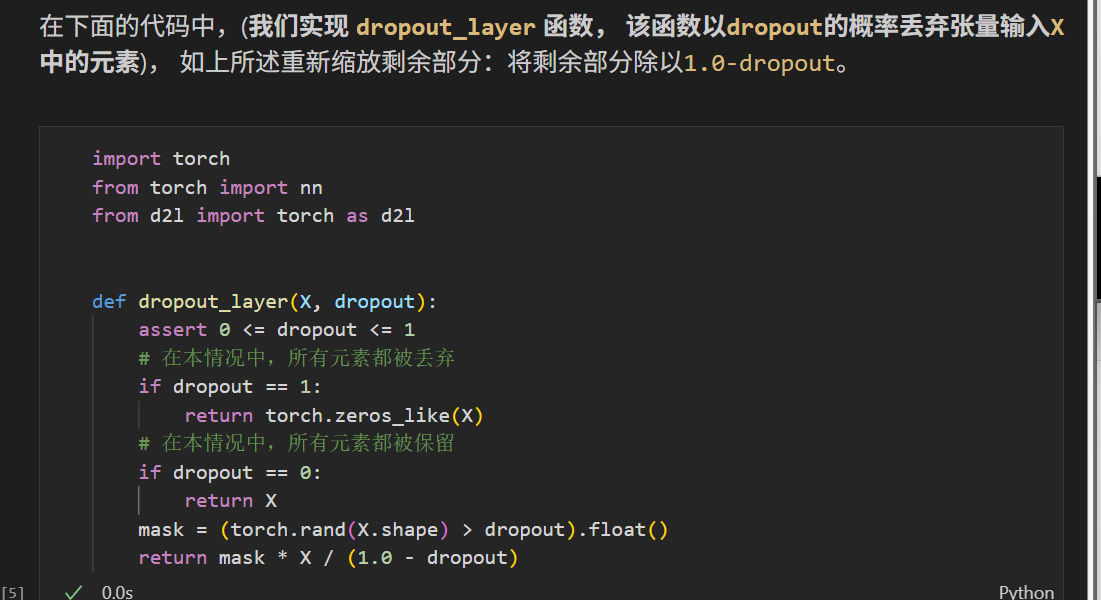
rand 随机生成0-1之间的均匀分布
- 训练

简洁实现
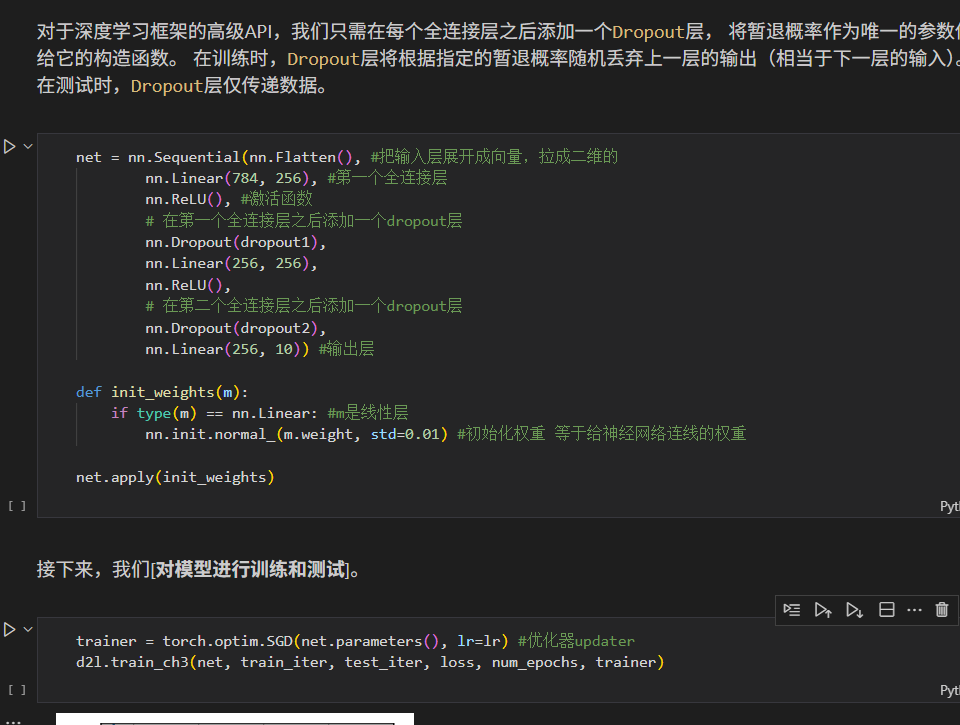
数值稳定性
神经网络的梯度
咱家使用反向传播求梯度
ht-1输入进来经过变换ft,变成输出ht
h1也就是输入层的输入X经过多层变换后输出h,y此时不是预测,y包含了损失函数和h
链式法则,对损失函数求导,进而得出梯度,wt为权重
考虑一个具有$L$层、输入$\mathbf{x}$和输出$\mathbf{o}$的深层网络。
每一层$l$由变换$f_l$定义,
该变换的参数为权重$\mathbf{W}^{(l)}$,
其隐藏变量是$\mathbf{h}^{(l)}$(令 $\mathbf{h}^{(0)} = \mathbf{x}$)。
我们的网络可以表示为:
$$\mathbf{h}^{(l)} = f_l (\mathbf{h}^{(l-1)}) \text{ 因此 } \mathbf{o} = f_L \circ \ldots \circ f_1(\mathbf{x}).$$
如果所有隐藏变量和输入都是向量,
我们可以将$\mathbf{o}$关于任何一组参数$\mathbf{W}^{(l)}$的梯度写为下式:
$$\partial_{\mathbf{W}^{(l)}} \mathbf{o} = \underbrace{\partial_{\mathbf{h}^{(L-1)}} \mathbf{h}^{(L)}}{ \mathbf{M}^{(L)} \stackrel{\mathrm{def}}{=}} \cdot \ldots \cdot \underbrace{\partial{\mathbf{h}^{(l)}} \mathbf{h}^{(l+1)}}{ \mathbf{M}^{(l+1)} \stackrel{\mathrm{def}}{=}} \underbrace{\partial{\mathbf{W}^{(l)}} \mathbf{h}^{(l)}}_{ \mathbf{v}^{(l)} \stackrel{\mathrm{def}}{=}}.$$
换言之,该梯度是$L-l$个矩阵
$\mathbf{M}^{(L)} \cdot \ldots \cdot \mathbf{M}^{(l+1)}$
与梯度向量 $\mathbf{v}^{(l)}$的乘积。
因此,我们容易受到数值下溢问题的影响.不稳定梯度带来的风险不止在于数值表示;不稳定梯度也威胁到我们优化算法的稳定性。
我们可能面临一些问题。
要么是梯度爆炸(gradient exploding)问题:
参数更新过大,破坏了模型的稳定收敛;
要么是梯度消失(gradient vanishing)问题:
参数更新过小,在每次更新时几乎不会移动,导致模型无法学习
梯度爆炸

对t-1层的输入h乘上权重Wt,再用上激活函数,作为t-1层的输出
对激活函数sigma进行求导,将【对t-1层的输入h乘上权重Wt,再用上激活函数】输入该函数后,将输出做一个对角矩阵【diag】,最后乘上权重Wt的转置
因此我们可以计算链式法则

relu(x)的导数如上图,对wihi-1求导后,矩阵里的元素不是1就是0
跟权重wi的转置T连乘,链式法则计算出的矩阵A一部分来自这个连乘,一部分为0
如果网络比较深,d-t很大,A里的值也有可能很大(如果Wi的值都大于1)
学习率太大->更大的梯度->w可能增加太大,权重更新超大
学习率太小->训练无进展
可能需要在训练过程不断调整学习率

梯度消失
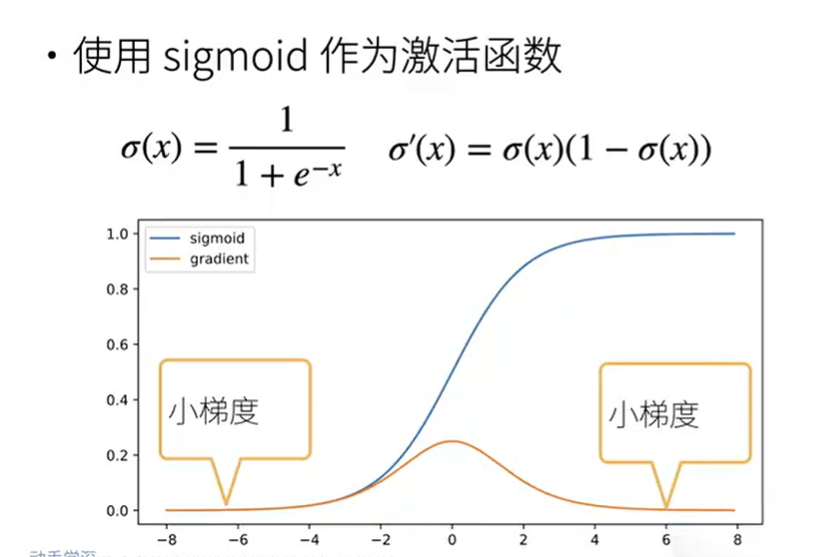
黄色为导数/梯度
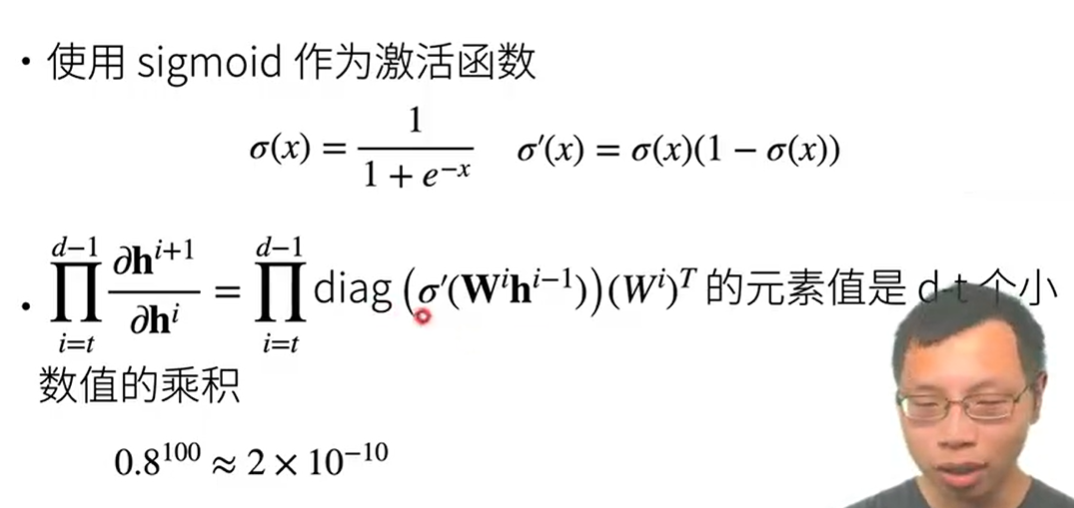
sigmoid导数在x轴上大部分的梯度非常小,diag()连乘很有可能是小数值连乘,越来越趋近于0那不就完蛋了嘛
总结:深度神经网络层数多,o=xw+b,h=sigma(o)一直从输入层向上传递,反向传播求梯度相当于层数个矩阵相乘,如果层数太多,矩阵值不稳定,过大会导致梯度爆炸
让训练更加稳定
合理的权重初始值和激活函数的选取可以提升数值稳定性
让每一层的输入和梯度的方差和均值都保持一致
 合理的权重初始和激活函数
合理的权重初始和激活函数
- 让每一层的方差是一个常数

将每一层都看成均值为0,反差为1
E 均值,Var 方差
损失函数关于第t层的输出的第i个元素的梯度
希望设计神经网络以达到这个性质
权重初始化


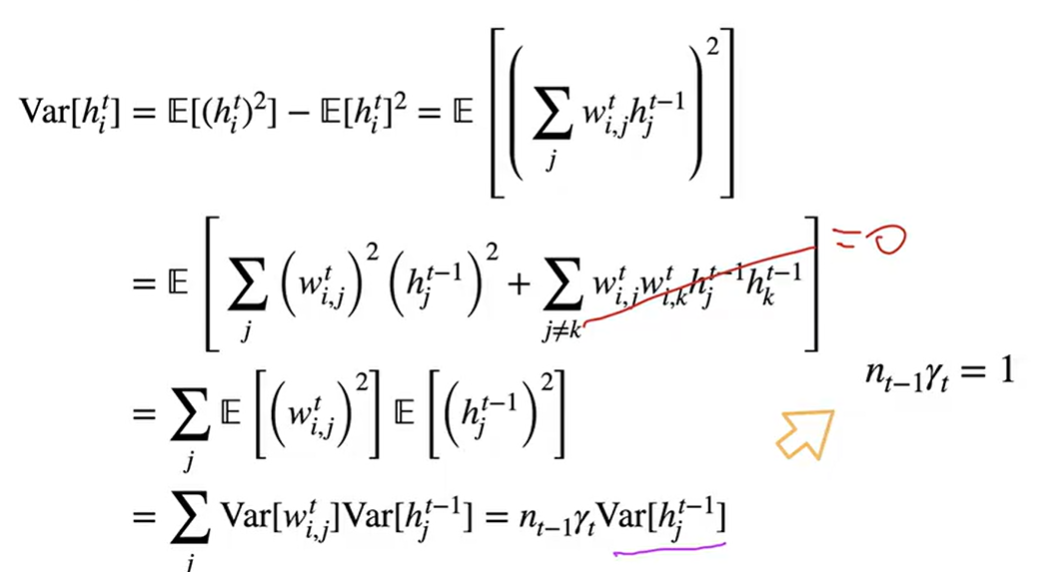
假设第t层的第i行第i列的w是一个独立同分布(有相同的概率分布),就可以说均值w为0,方差w为gamma-t,t为层数
第t-1层->第t层的输入独立于w
假设没有激活函数,Ht=Wt Ht-1
计算过程如上
独立同分布的a,b均值E[ab]=0
假设输入的方差等于输出的方差

第一个公式满足前向输出的均值和方差相同
第二个公式满足梯度输出的均值和方差相同
Xavier

nt-1 很难等于nt,除非你的输入个数等于输出
取个折中:Xavier
权重初始化时的方差根据输入和输出的个数进行初始化
激活函数

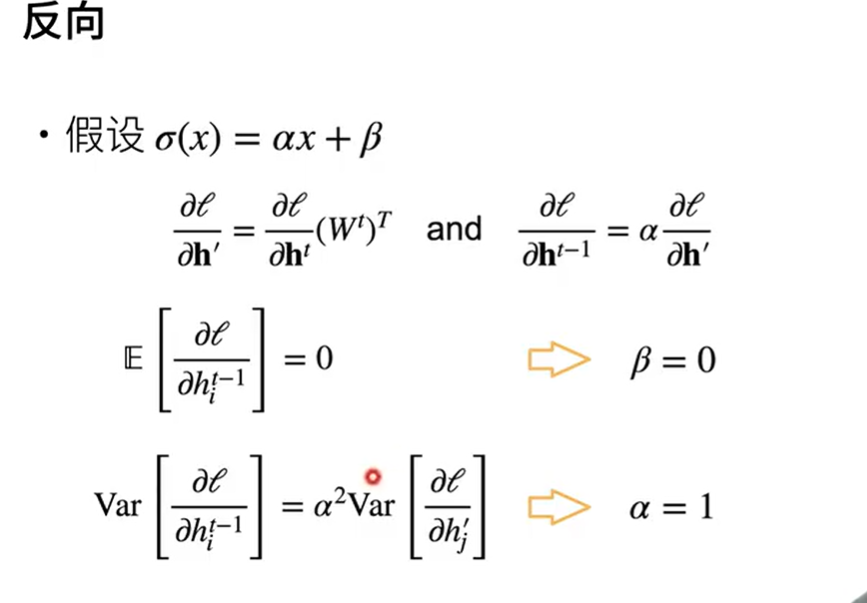
∂h∂ℓ:损失对隐藏状态的梯度
! ht = α ht-1 * Wt +β
∂ht/ ∂ht-1 = α * Wt
∂ loss/ ∂ht-1 = (∂ loss/∂ ht)* *α * Wt
说明激活函数要为f[x]=0+x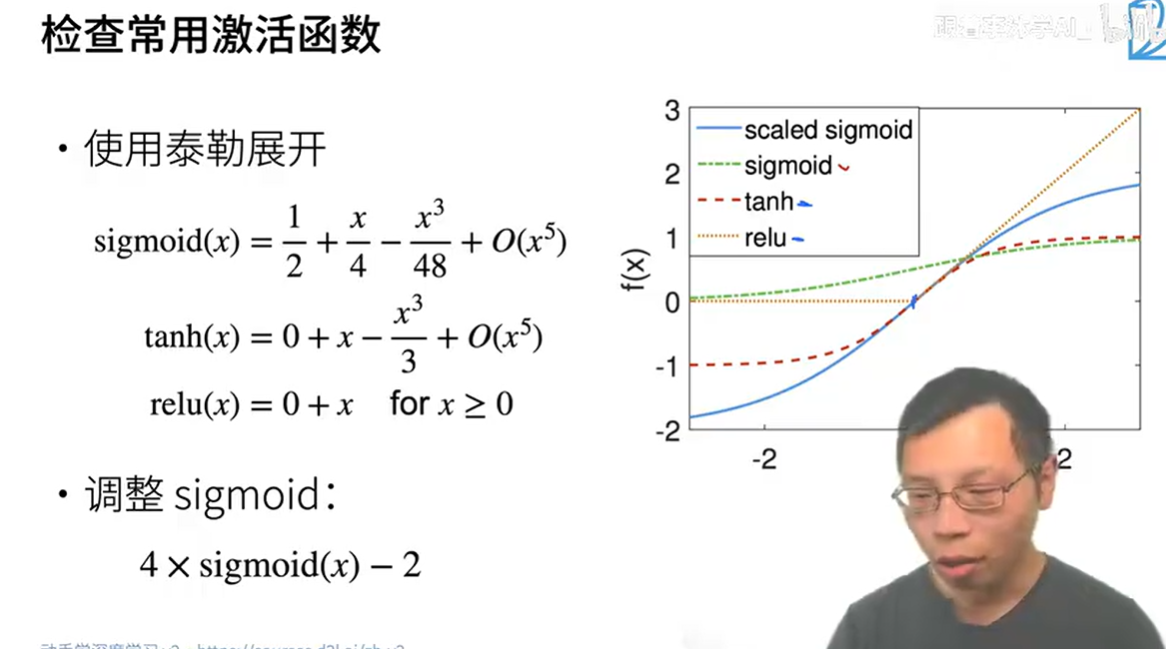
在零点附近近似于0+x
答疑
梯度爆炸:每层的输出太大 合理的权重初始化
梯度消失:激活函数本身的梯度很小 合理的激活函数
数值稳定性让数值在一个合理的区间,让硬件更好处理,不影响模型表达性
权重在每个iterator,每个批量Batch都更新一次,也就是说在每一个特征向量输入后都进行更新
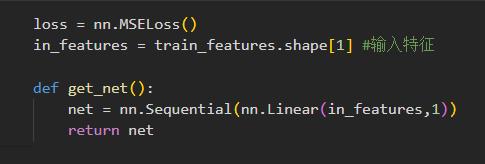
kaggle:预测房价
数据预处理
pands库基础操作

读取数据集后,将训练和测试集放在一起标准化数据
将缺失值变成0

处理离散值 字符串

用独热编码对离散值进行编码

将 df转换成np在转化成tensor
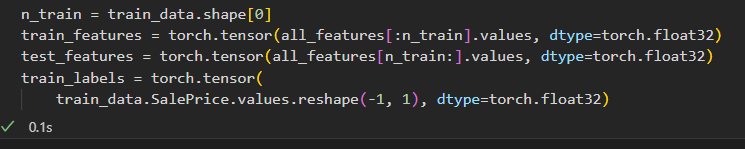
df底层是用np创建的,调用value返回一个np数组
训练
pytorch nn模块是构建和训练神经网络的模块,详见api参考手册
- 线性模型
- 用相对误差进行训练评价


- 使用adam优化器,对学习率敏感
- k折交叉验证
参数管理
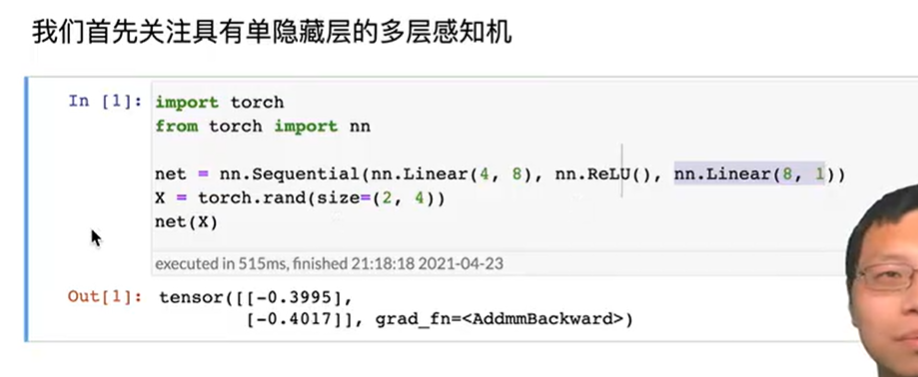
可以把net简单理解为list,net[2]拿到的就是nn.linear输出层
参数访问
- 直接访问目标参数,参数:weight,bias
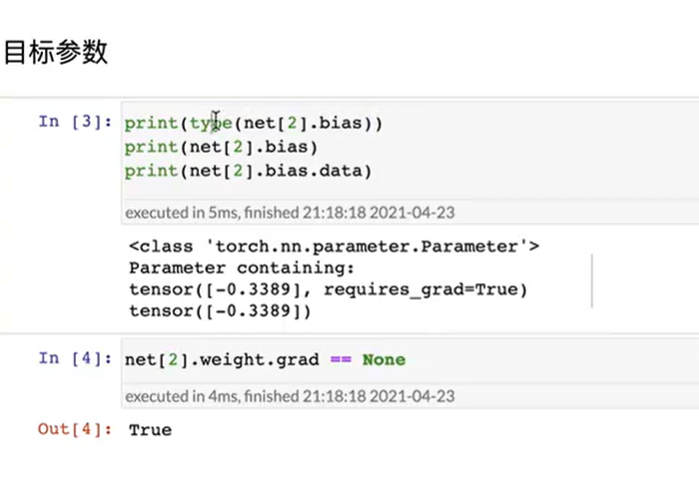
[!NOTE]
参数是复合的对象,包含值、梯度和额外信息。
这就是我们需要显式参数值的原因。
除了值之外,我们还可以访问每个参数的梯度。
在上面这个网络中,由于我们还没有调用反向传播,所以参数的梯度处于初始状态。
- 一次性访问所有参数
net.named_parameters()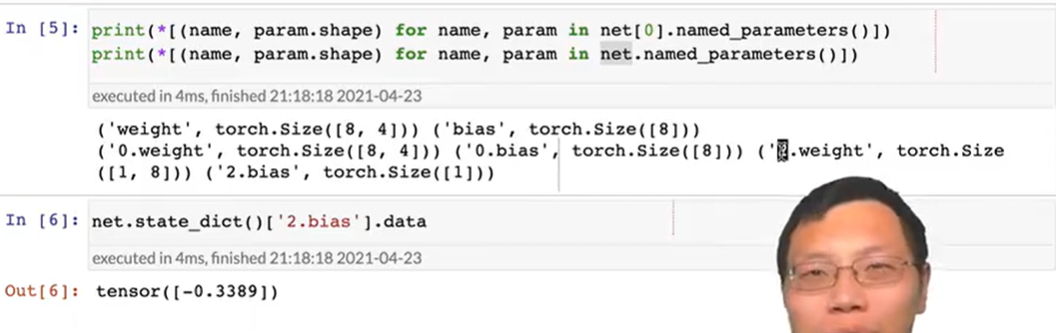 0.weight 0.bias分别是第一个全连接层的参数名称,所以也可以这么访问
0.weight 0.bias分别是第一个全连接层的参数名称,所以也可以这么访问
net.state_dict()[‘2.bias’].data - 从嵌套块收集参数
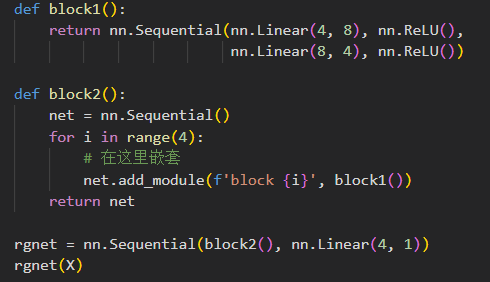 嵌套块的结构如下
嵌套块的结构如下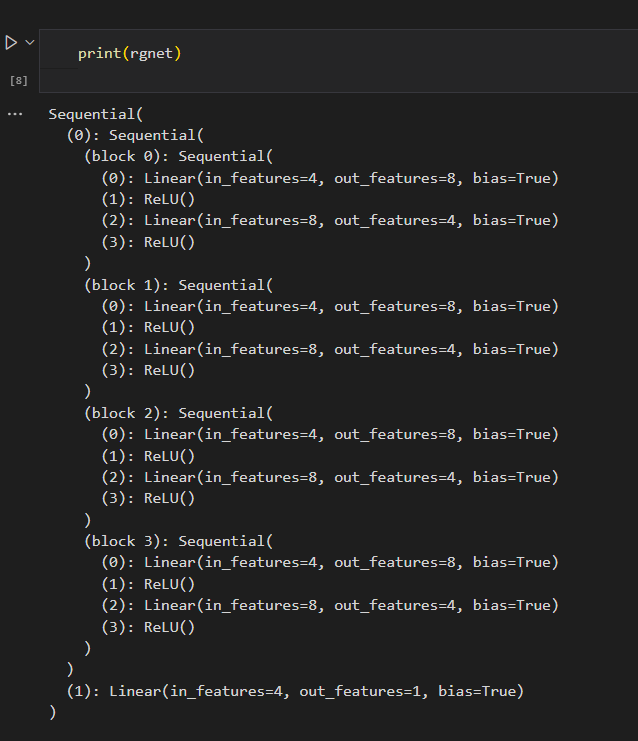
可以像嵌套列表一样索引他们
参数初始化
使用nn中内置的初始化函数
- 将线性层初始化为标准差为0.01,bias设置为0 正态分布
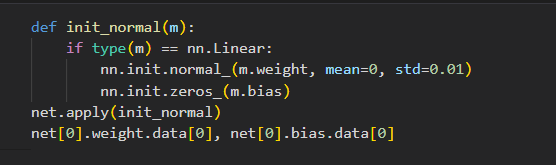
- Xavier初始化方法
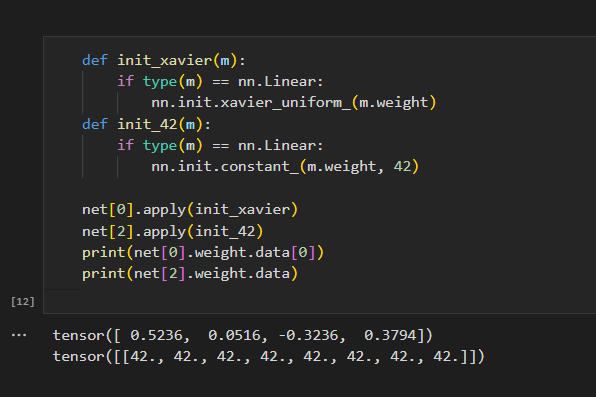
自定义初始化
使用以下的分布进行w的参数初始化
$$
\begin{aligned}
w \sim \begin{cases}
U(5, 10) & \text{ 可能性 } \frac{1}{4} \
0 & \text{ 可能性 } \frac{1}{2} \
U(-10, -5) & \text{ 可能性 } \frac{1}{4}
\end{cases}
\end{aligned}
$$
参数绑定
有时我们希望在多个层间共享参数:
我们可以定义一个稠密层,然后使用它的参数来设置另一个层的参数。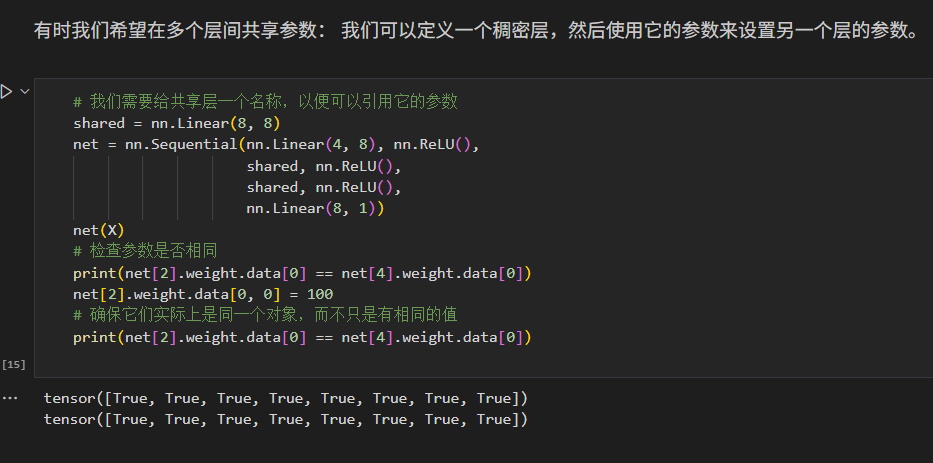
[!NOTE]
这里有一个问题:当参数绑定时,梯度会发生什么情况?
答案是由于模型参数包含梯度,因此在反向传播期间第二个隐藏层
(即第三个神经网络层)和第三个隐藏层(即第五个神经网络层)的梯度会加在一起。
自定义层
当我们需要自己发明一个现在在深度学习框架中不存在的层,必须构建自定义层
构造CenterdLayer类,继承自nn.Module

将层作为组件合并带更复杂的模型中
这里的CenterdLayer负责类似激活函数的工作,将输入减去均值再输出
让我们把不同的层组合起来
带参数的自定义层-一个自定义的全连接线性层
- 用nn.Parameters方法进行初始化,weight,bias数据此时用.data调用
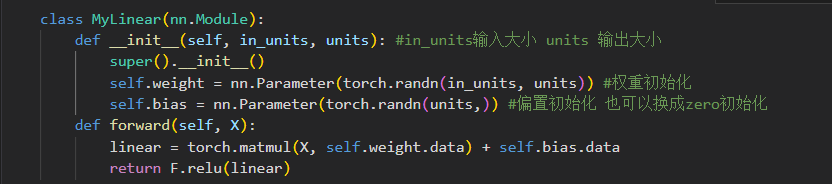
- 用nn.Parameters方法进行初始化,weight,bias数据此时用.data调用
用自定义层直接执行前向传播计算(y=net(x))

也可以用自定义层直接构建模型

读写文件
就是怎么存训练好的东西
加载保存张量
- torch.save
- 存储 单个张量
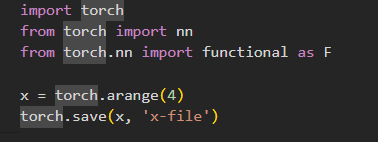
- 存储张量列表
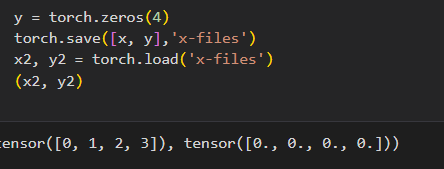
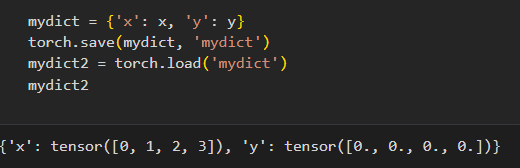
- 读取和存储字典,x->tensorX,y->tensorY
- 存储 单个张量
- torch.load
- 读取单个张量
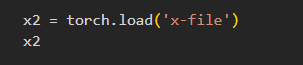
- 读取单个张量
加载和保存整个模型网络-保存模型参数
模型本身难以序列化,我们需要用代码生成架构,然后从磁盘加载参数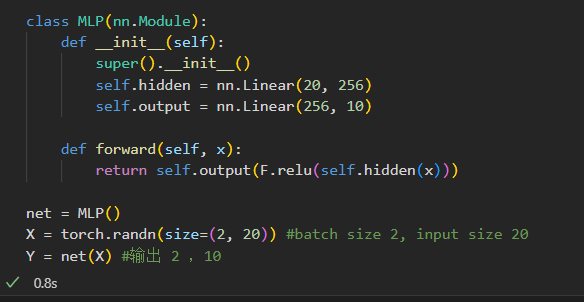


Q&A
- 处理离散值(字符串)时内存炸掉了怎么办:不要用独热编码了,用其他的特征表达方法
- net(X)=net.forward(X)
- 参数初始化,不要让模型一开始训练就炸掉,不太影响后面的精度
使用GPU
前提-装cuda和驱动
- 查看GPU nvidia-smi
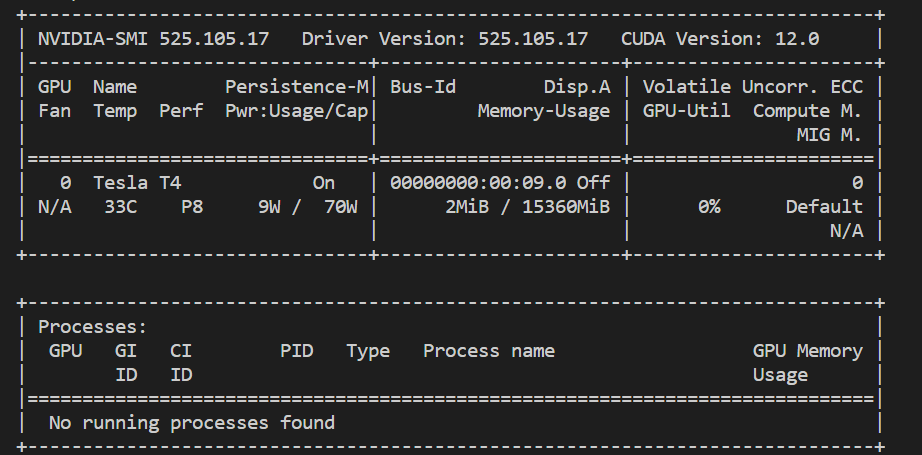
- 指定用gpu,默认情况下都在cpu
- 在pytorch中
1 | |
- 查询cpu的数量
1 | |
张量与GPU
- 查询tensor所在的设备
1 | |
- 在gpu上创建张量
1 | |
复制 假设我们有两个gpu,虽然我只有一个,我可以执行一个脱裤子放屁的操作,在gou之间传输数据
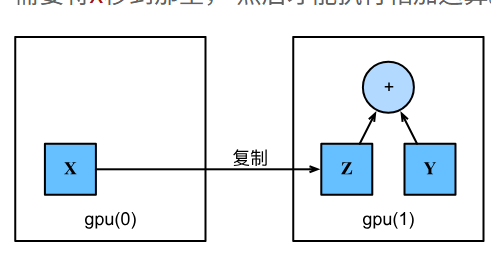

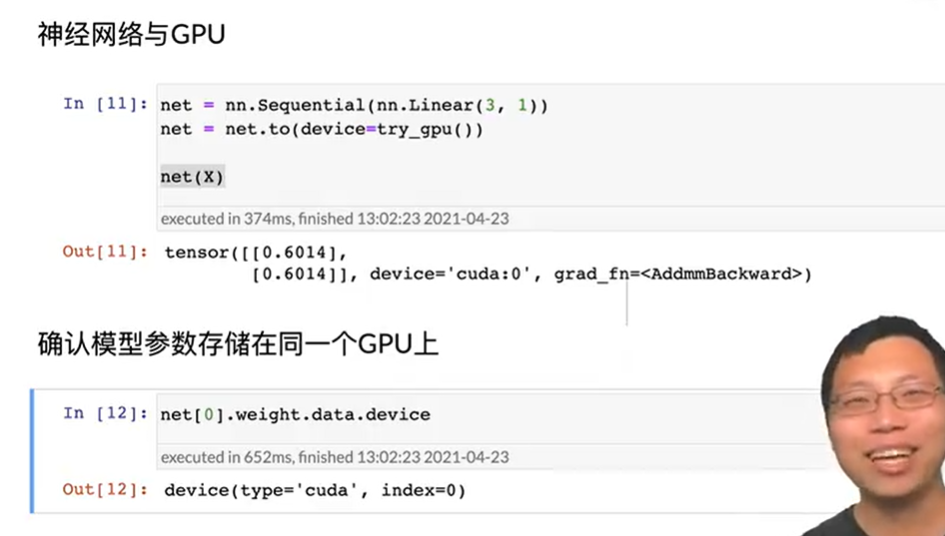
现在你可以对他们进行运算了^-^神经网络与gpu
卷积神经网络
前情提要
mlp很适合处理表格数据,行对应样本,列对于特征
如果特征特别多,比如图片,超级局限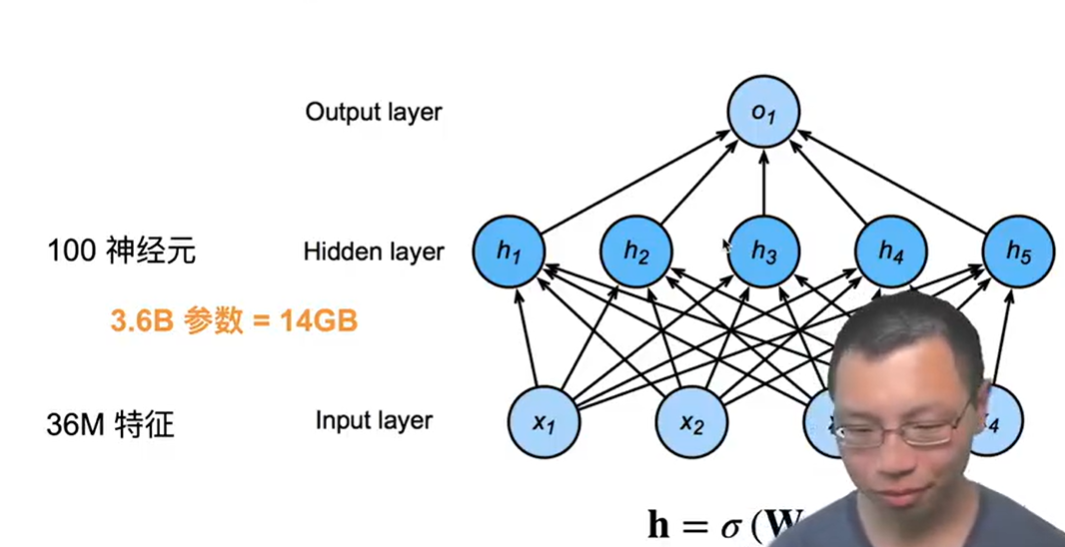
卷积神经网络就是机器学习利用自然图像中一些已知结构的创造性方法
- 两个原则 平移不变性,局部性
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
重新考察全连接层
- 将输入和输出变形为二维矩阵 不太理解
- 将权重变形为4-D张量,我的理解是,权重等于[输入,输出]这样的形状,输入输出变成二维,权重就变成四维
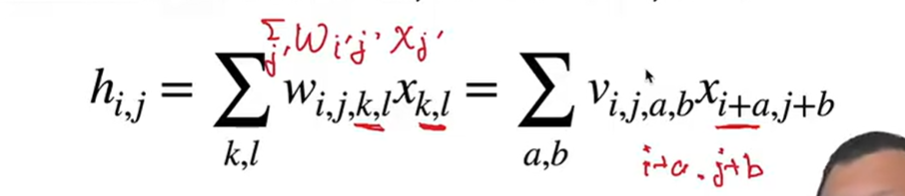
- 为w进行重新索引
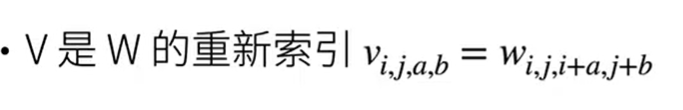
[!NOTE] Title
(i,j)表示x在图像中的位置,(k,l)为输入x的维度,二维矩阵)
索引$a$和$b$通过在相对坐标(i,j)的正偏移和负偏移之间移动覆盖了整个图像。
对于隐藏表示中任意给定位置($i$,$j$)处的像素值$[\mathbf{H}]{i, j}$,可以通过在$x$中以$(i, j)$为中心对像素进行加权求和得到,加权使用的权重为$[\mathsf{V}]{i, j, a, b}$。
原则 1 平移不变性
$$[\mathbf{H}]{i, j} = u + \sum_a\sum_b [\mathbf{V}]{a, b} [\mathbf{X}]_{i+a, j+b}.$$
由于
我们要找到一个解决方案让v(图像识别器)不依赖于(i.j),(i,j)为x在图像中的坐标,如果x进行了平移,我们要保证权重v不变,即平移不变性
所以我们简化解决方案为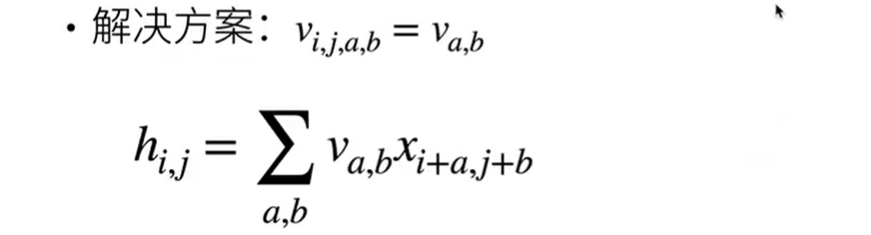
这就是卷积,在数学中叫做交叉相关
[!NOTE] Title
V不再依赖图像中位置,不需要存那么多信息,这是显著的进步
原则2 局部性
计算(i,j)处的输出H时,我们只要(i,j)附近的参数,太远的不要
解决方案:
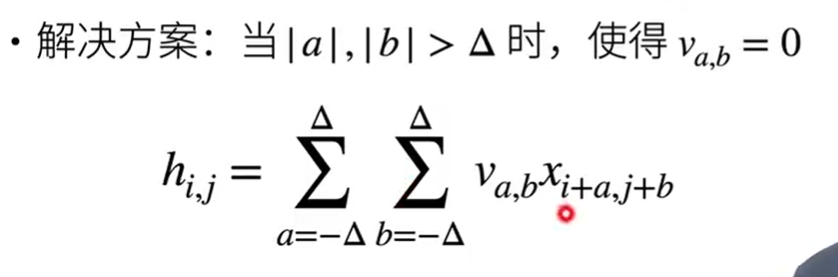
这样我们只在相对(i,j)的一部分a,b的偏移进行计算
通道

总结
- 图像的平移不变性使我们以相同的方式处理局部图像,而不在乎它的位置。
- 局部性意味着计算相应的隐藏表示只需一小部分局部图像像素。
- 在图像处理中,卷积层通常比全连接层需要更少的参数,但依旧获得高效用的模型。
卷积层
- 输入 X
- 卷积的核(kernel) W/V
- 输出
卷积窗口滑动
卷积窗口的形状由内核v形状决定
结合公式进行理解
==输出大小由输入和内核共同决定==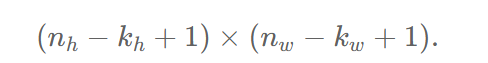
二维卷积层
- 学习参数:核矩阵和偏移是可学习的参数,核矩阵的大小是超参数
注意这里的⭐不是矩阵运算,时上述定义的卷积窗口,二维互相关运算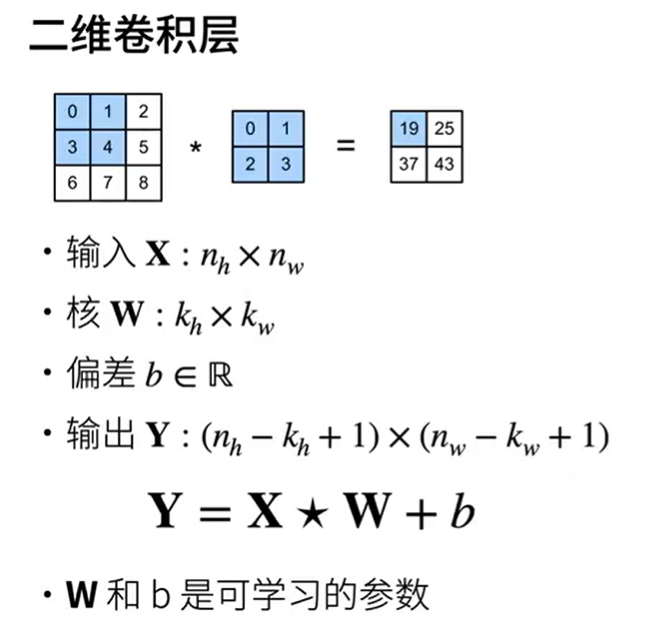
[!NOTE] Title
不同的卷积核对图片有不同的处理效果,比如边缘检测,锐化,高斯模糊
神经网络可以通过不同的核去得到不同的效果

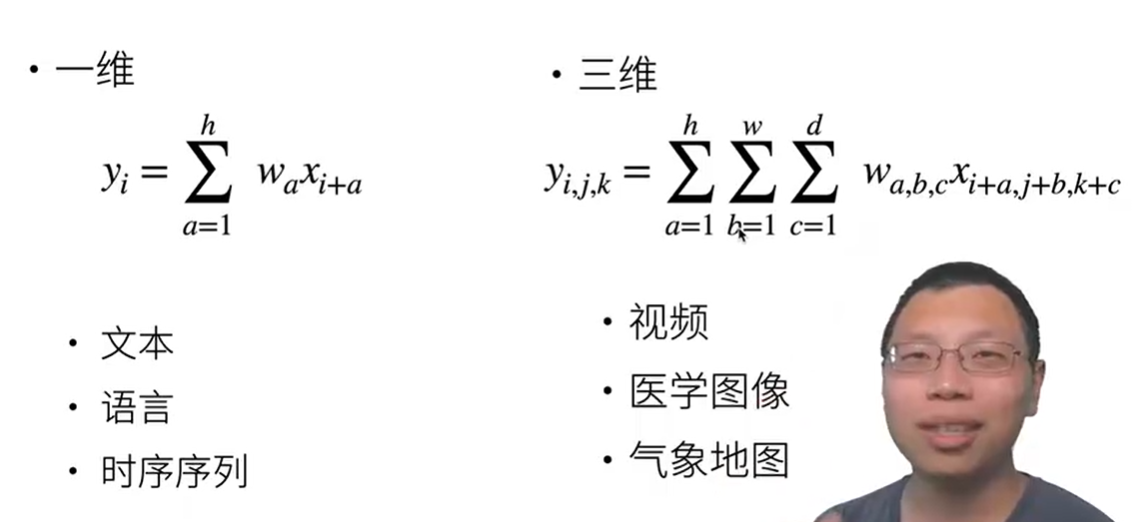
一维/三维交叉相关(卷积)
二维卷积层的代码实现


学习卷积核
手动设计滤波器很难,我们可以通过学习来生成滤波器
通过仅查看输入-输出来学习X生成Y的卷积核
- 代码实现 用nn内置卷积层

填充和步幅
- 填充和步幅都是卷积层的超参数
太多卷积层,图像会丢失很多像素,我们可以用填充解决这个问题
如果我们要大幅降低图像的高度和宽度,可以用步幅解决
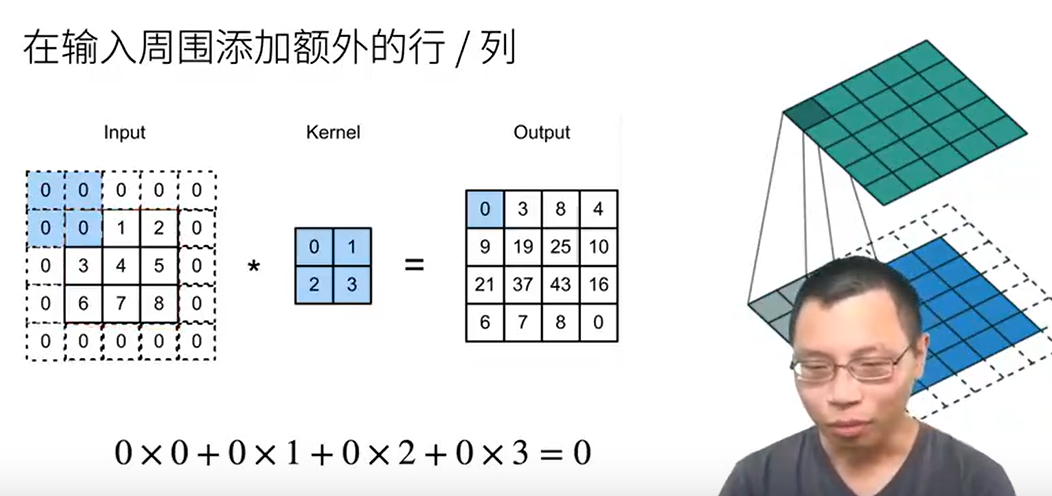
填充
在输入周围添加额外的行/列
 -
-
规则:这样填充不会改变输出的大小,ph和kh正好消掉
步幅
步幅指的是行/列的滑动步长,之前都是默认向下滑动一格,向右滑动一格,步幅可以成倍的减少输出形状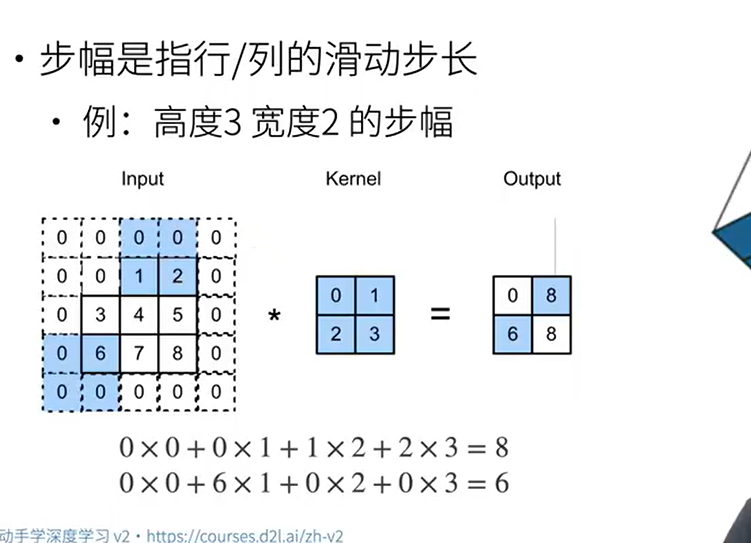
输出形状:
代码实现
- 填充:在所有侧边填充一个像素

- 步幅

- 一般使用比较对称的情况
多输入和输出通道
多输入通道
- 彩色图片有RGB三个通道 形状为三维的3* h * w
- 怎么做卷积呢?
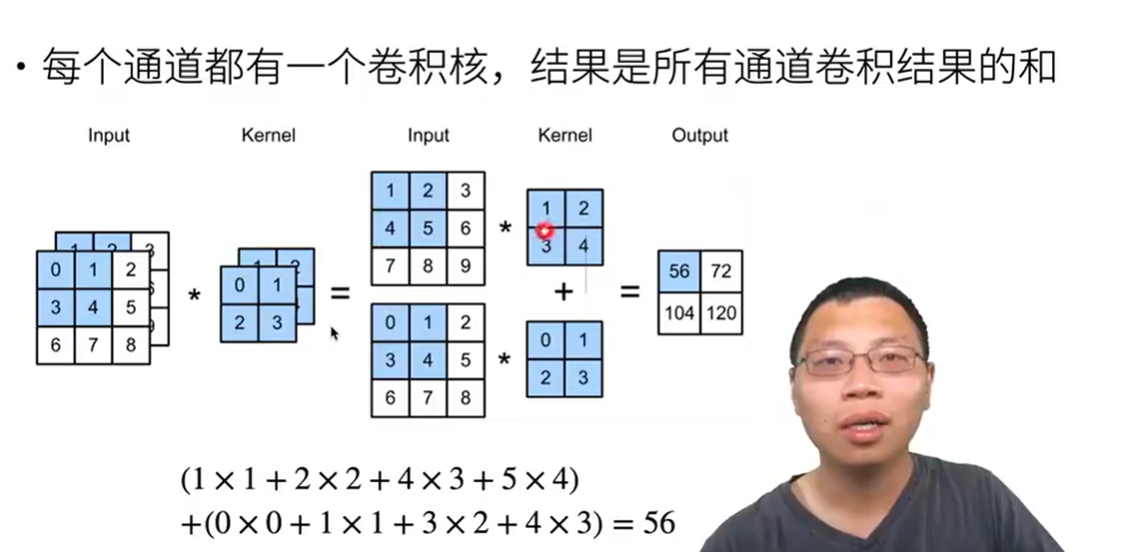
- 公式表达
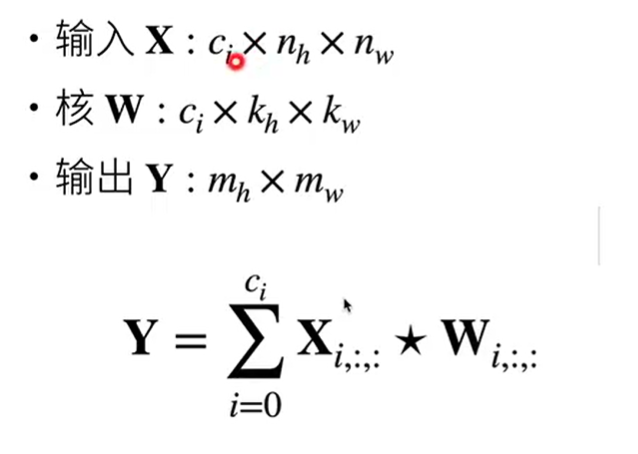
- 输出是一个单通道
多输出通道
- 每个输出通道对应不同的三维卷积核

- 作用

1 * 1卷积层
相对于对输入的每个通道的像素做加权和,融合通道
1 * 1卷积唯一的计算发生在通道上,失去了对空间模式的识别
相当于将input拉长成一位数组h* w,h * w作为行数,通道数ci作为列数,与权重维度为(co,ci)的矩阵相乘,得到的结果为h*w ,co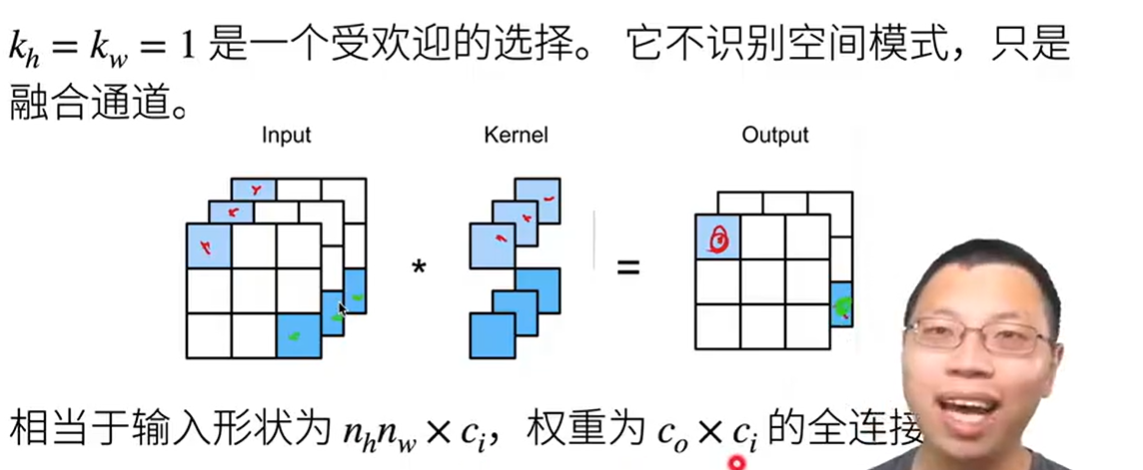
全连接层
二维卷积层终极形态
[!NOTE] 参数解释
co 输出通道数
ci 输入通道数
nh ,nw 输入的高,宽
kh,kw 核(权重)的高宽
mh,mw输出的高,宽

- 复杂度:需要的浮点计算数

代码实现
多输入通道
多输入输出通道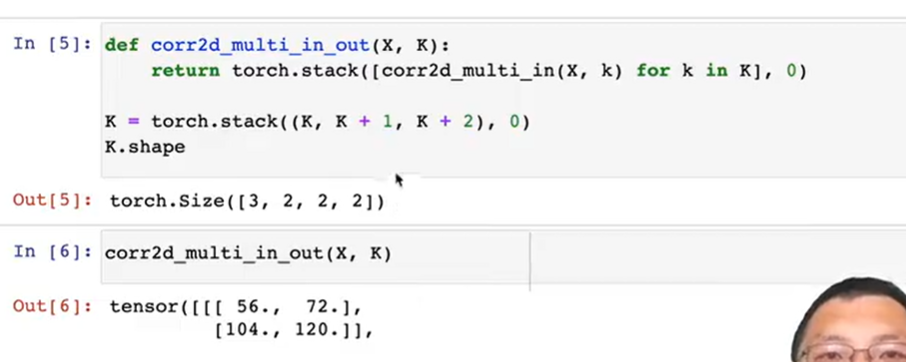
池化层
卷积对位置过于敏感,我们需要降低卷积层对位置的敏感性
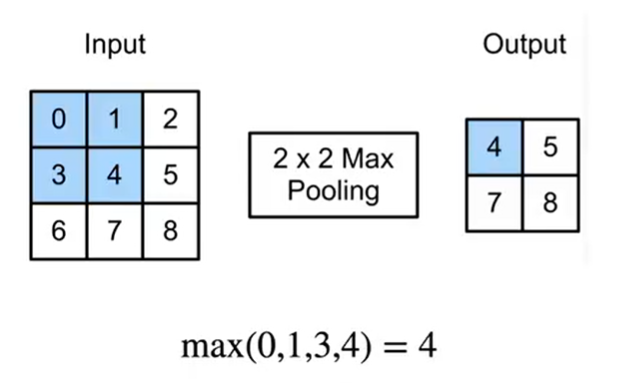
二维最大池化层
- 返回滑动窗口中的最大值,可容忍像素移位,返回的是每个窗口最强的模式信号
- 填充,步幅核多个通道
- 输出通道等于输入通道数,不会融合多输入通道
- 没有可学习的参数
平均池化层
将最大池化层的最大操作替换平均
代码实现
二维输入X的简单代码实现
pytorch内置函数实现填充和步幅
- 默认情况下,pytorch的步幅和池化窗口的大小相同
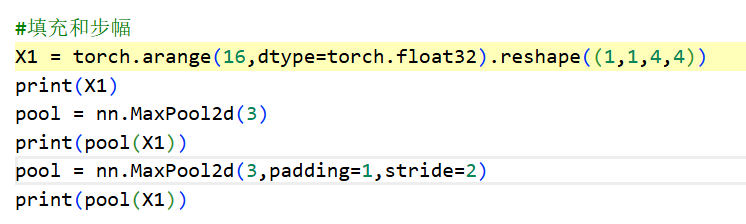
- 多通道实现

- 这里的3指的是池化层的尺寸
LeNet
[!NOTE]
不同于mlp的是,卷积神经网络让我们能保留图片的空间信息(还记得我们在mlp处理图片时时展平成一维tensor吗)
MINST数据集,无数学子的第一个数据集,让我们来识别数字吧
- letnet是什么
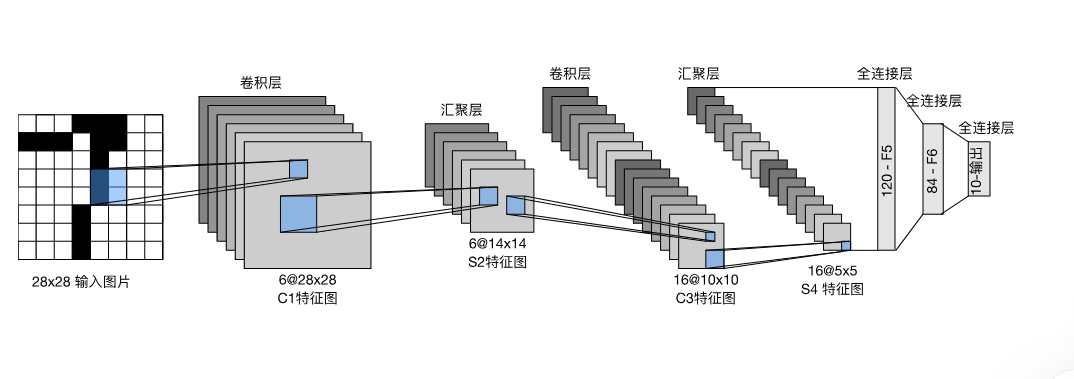
先使用卷积层学习图片空间信息,通过全连接层来转换到类别空间 - 代码实现
- 原始的数据集是32* 32,我们reshape的时候每边去掉了2行。所以卷积层要多padding一下
- 非线性关系,在卷积层后用Sigmoid()函数
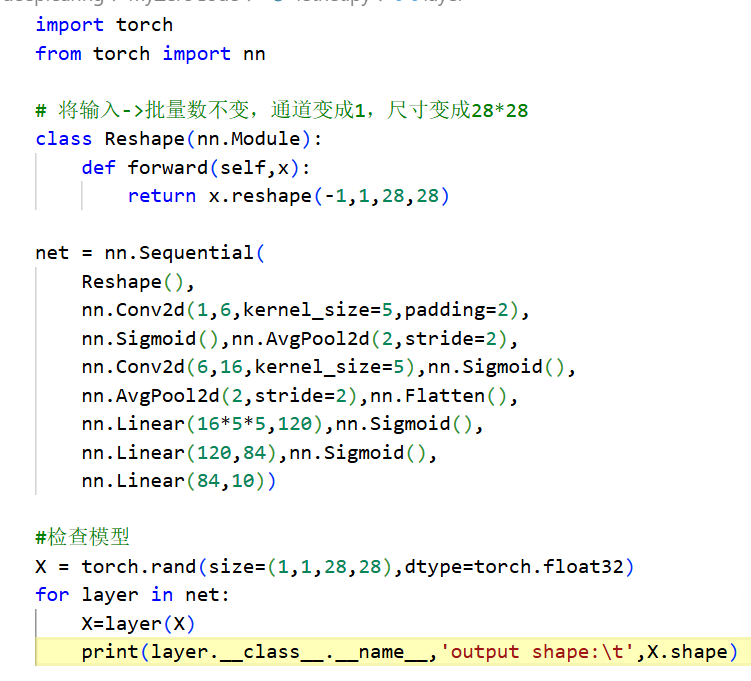
- 输出

从以上输出可以看出卷积神经网络的设计思想,将图片大小不停压缩,将通道增加,将信息分散到通道中,最后图片高宽变成1,通道变成上千
现代卷积神经网络
AlexNet
更深更大的letnet,相对于letnet
- 加入了丢弃法
- AlexNet采用Relu作为激活函数,LetNet用Sigmoid作为激活函数
- MaxPooling
通过CNN学习特征,再用softmax回归分类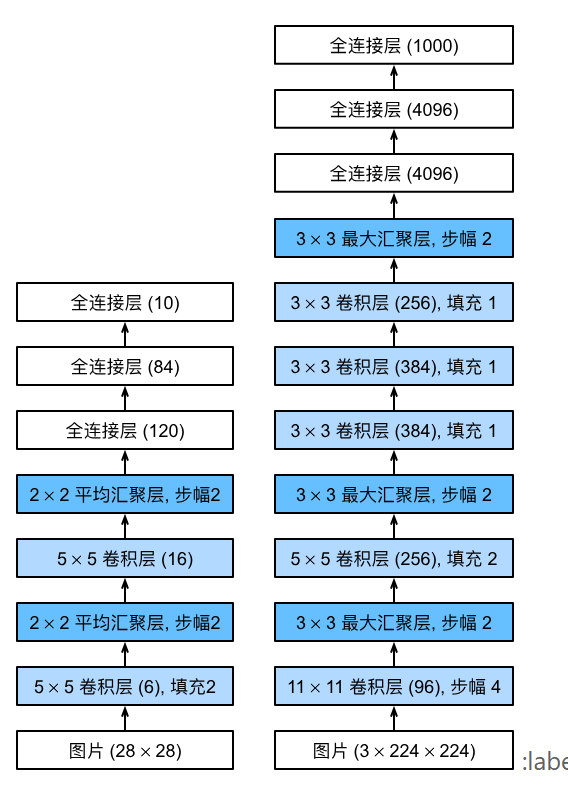
- 更多细节
- 激活函数由sigmoid->relu(减缓梯度消失)
- 隐藏全连接层后加入了丢弃层
- 数据增强
- 代码实现

- 模型验证

- 模型验证
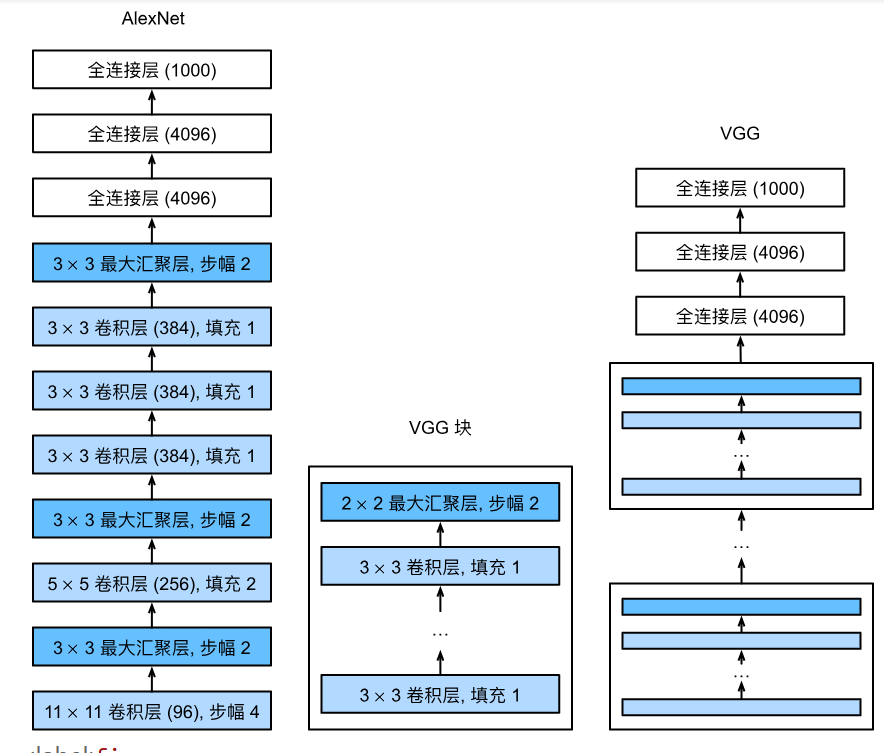
VGG
将卷积层组合成快
- VGG块
- 3 * 3卷积 n层,m通道(VGG块中每个卷积层的通道数是一样的)
- 2 * 2 最大池化层(步幅2)
[!NOTE] 为什么用3 * 3卷积,不用5 * 5卷积
深但窄效果更好
- 多个VGG块后接全连接层
- 代码实现
- vgg块的超参数:层数,输入通道数,输出通道数


- vgg块的超参数:层数,输入通道数,输出通道数
nin
[!NOTE] Title
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。
AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。
全连接层存在的问题:
- 很容易过拟合
- 很大矩阵运算,需要不停访问内存-
Nin 取消了全连接层,使用nin块
- 一个卷积层后跟两个1 * 1 卷积层
- 步幅1,无填充,输出形状和卷积层输出一样
- 起到全连接层的作用,对通道进行一些混合的操作
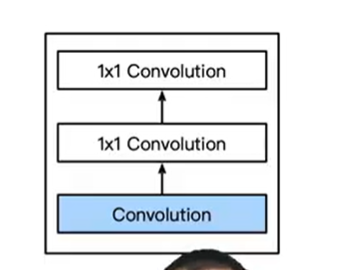
nin 架构

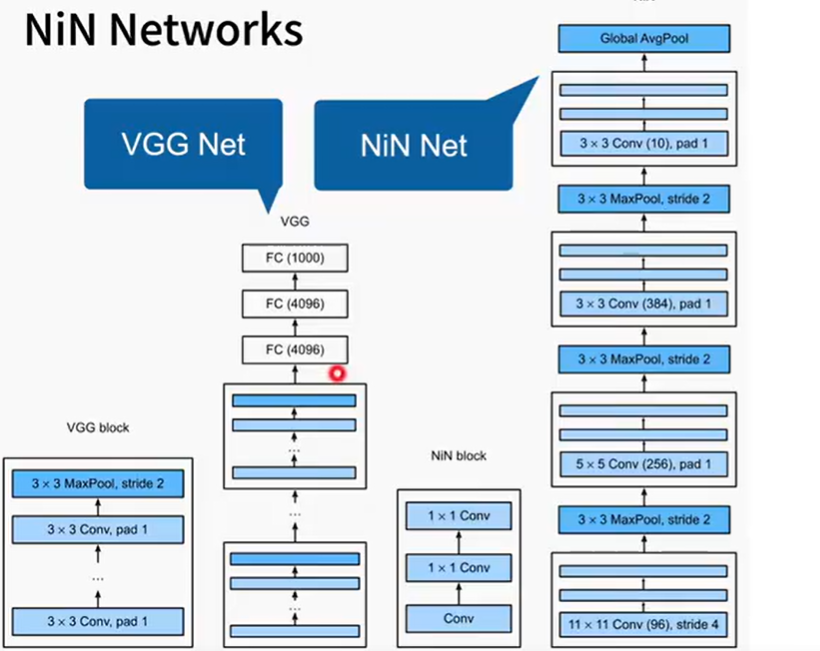
[!NOTE] 总结
- nin 块中的两个1 * 1卷积层对每个像素增加了非线性性
- nin使用全局平均池化层来替代vgg和alexnet中的全连接层,不容易过拟合,更少的参数个数
- 代码实现


GoogleNet
含并行连结的网络
- inception块 基本的卷积快
- 四个路径从不同层面抽取信息,然后在输出通道维合并