hnuOs小班课:沙盒技术,容器技术与Docker
简单说说容器/沙盒(Sandbox)以及Linux seccomp_linux沙盒-CSDN博客
漫谈容器化技术(docker原理篇)-阿里云开发者社区 ppt 参考这个改
沙箱技术: sandboxing
sandbox总述
https://www.proofpoint.com/uk/threat-reference/sandbox
android应用沙盒
https://source.android.com/docs/security/app-sandbox?hl=zh-cn
- 保护机制“
[!NOTE]
Android 平台利用基于用户的 Linux 保护机制识别和隔离应用资源,可将不同的应用分隔开来,并保护应用和系统免受恶意应用的攻击。为此,Android 会为每个 Android 应用分配一个唯一的用户 ID (UID),并在自己的进程中运行。
Android 会使用该 UID 设置一个内核级应用沙盒。内核会在进程级别利用标准的 Linux 机制(例如,分配给应用的用户 ID 和组 ID)实现应用和系统之间的安全防护。默认情况下,应用不能彼此交互,而且对操作系统的访问权限会受到限制。如果应用 A 尝试执行恶意操作(例如在没有权限的情况下读取应用 B 的数据或拨打电话),系统会阻止此类行为,因为应用 A 没有相应的默认用户权限。这一沙盒机制非常简单,可审核,并且基于已有数十年历史的 UNIX 风格的进程用户隔离和文件权限机制。
由于应用沙盒位于内核层面,因此该安全模型的保护范围扩展到了原生代码和操作系统应用。位于内核之上的所有软件(例如,操作系统库、应用框架、应用运行时和所有应用)都会在应用沙盒中运行。某些平台会限制开发者只能使用特定的开发框架、API 或语言。在 Android 上,并没有为了强制执行安全防护机制而限制开发者必须如何编写应用;在这方面,原生代码与解释型代码一样会被沙盒化。
linux应用沙盒:
chroot系统调用
切换系统的根目录,只有root用户才能调用
实际操作
将/bin/bash,/bin/ls复制到chroot-test目录中
查看bash,ls的依赖库,按照以下目录结构将依赖库复制入chroot-test中
sudo chroot . /bin/bash运行
chroot-test结构如下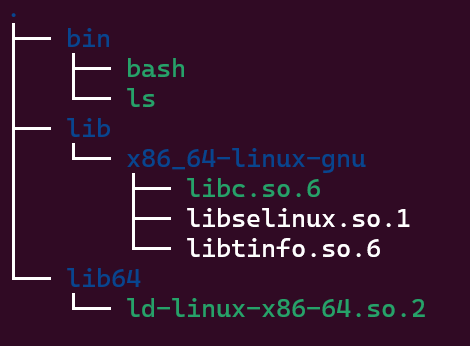
运行:
可以看到我们的根目录已经切换
seccomp
ssecomp
让进程只能执行特定的systemcall,供sangBox开发人员使用的工具(Android,systemd,QUMU,Docker,Firejail,等)
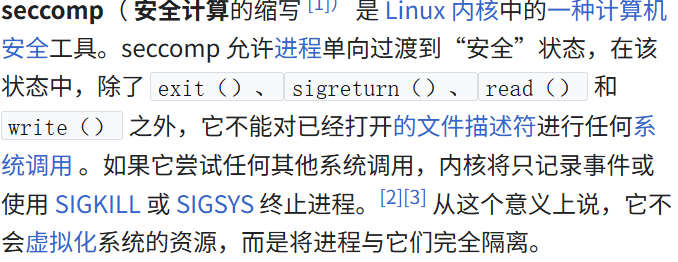

应用实践:
- zero code seccomp:外部作员可以将所需的沙箱策略注入任何进程,而无需修改任何源代码。
systemd:Systemd 是“零代码 seccomp”方法的流行实现之一。Systemd 托管服务可以在其单元文件中定义SystemCallFilter=指令,其中列出了允许托管服务进行的所有系统调用。
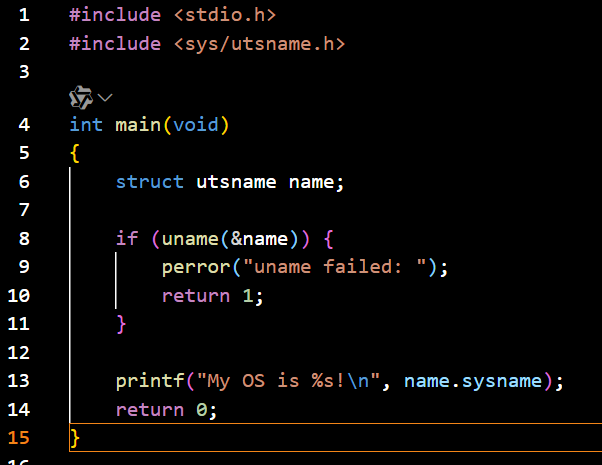
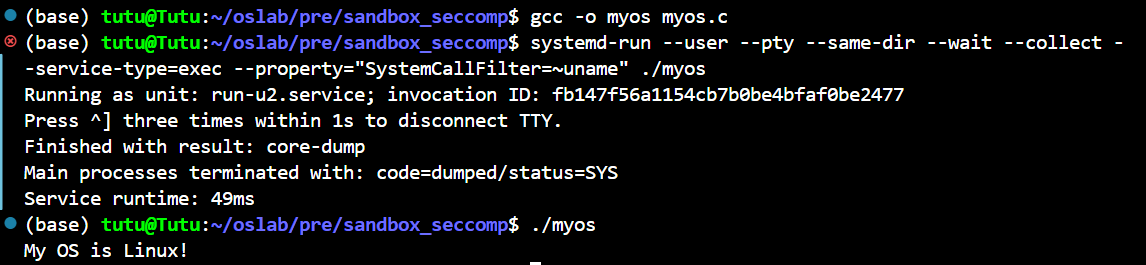
[!NOTE]
Systemd是系统启动的第一个进程(PID 1),负责初始化硬件、挂载文件系统、加载内核模块,并启动用户空间的服务,它通过并行化服务启动显著缩短了系统启动时间(相比传统串行方式提升30%-50%)systemd-run是 systemd 生态中的命令行工具,用于临时运行命令或服务,并生成瞬态的 systemd 单元(如.service、.scope或.timer)。这些单元在任务完成后自动消失,适合单次或短时任务的管理
[!NOTE]
在用户级沙箱环境中运行./myos程序,具体表现为:
资源隔离:通过 cgroups 限制进程资源,并通过 seccomp 过滤
uname系统调用交互支持:伪终端(PTY)允许程序与用户输入输出交互。
生命周期管理:进程结束后自动清理临时单元,避免资源泄漏
同步执行:
--wait确保脚本或命令行在此任务完成后继续执行后续操作
cgroups
cgroups8c)ppt参考
cgroups 的全名叫做 Control Groups,他是 Linux Kernel 中的功能,可以用來限制,控制與隔離 Process 所使用到的系統資源,例如 CPU, Memory, Disk I/O, Network…等
cgroups本身没有提供类似api或者lib的操作方式,它是透过linux virtual file system所实作出来,操作它跟操作一般的档案系统没什么两样
我们可以单纯操作文件系统,或者通过cgroups driver(systemd)来使用它;
- 通过操作文件系统粗略了解cgroup如何控制task使用的资源
- cgroups v1 每个子系统独立挂载
- 查看所有挂载点
- (/sys/fs/cgroup/${subsystem})
- 一個 Subsystem 負責管理一種資源,例如 CPU 或是 Memory,不同的作業系統所提供的 Subsystem 種類可能不盡相同,以下列出一些常見的類型
- 在memory中添加democgv1,建立一个democgv1的cgroup,由memory的subsystem控制资源,所以里面新增的东东都与memory相关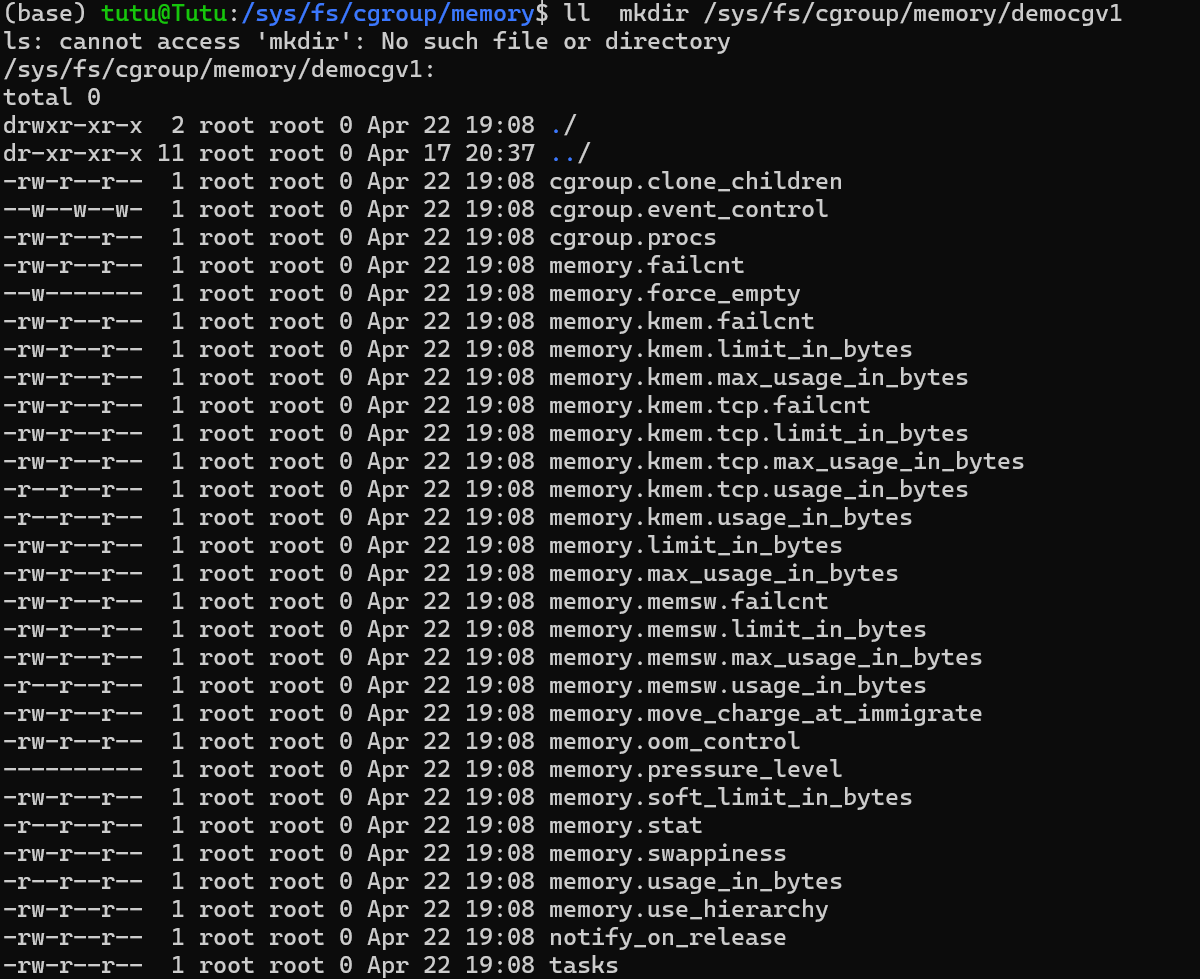
[!NOTE]
📖 Task: 運行於作業系統內的 Process,在 cgroups 內被稱為 Task📖 Subsystem: 一種資源控制器,一個 Subsystem 負責管理一種資源,例如 CPU 或是 Memory,不同的作業系統所提供的 Subsystem 種類可能不盡相同
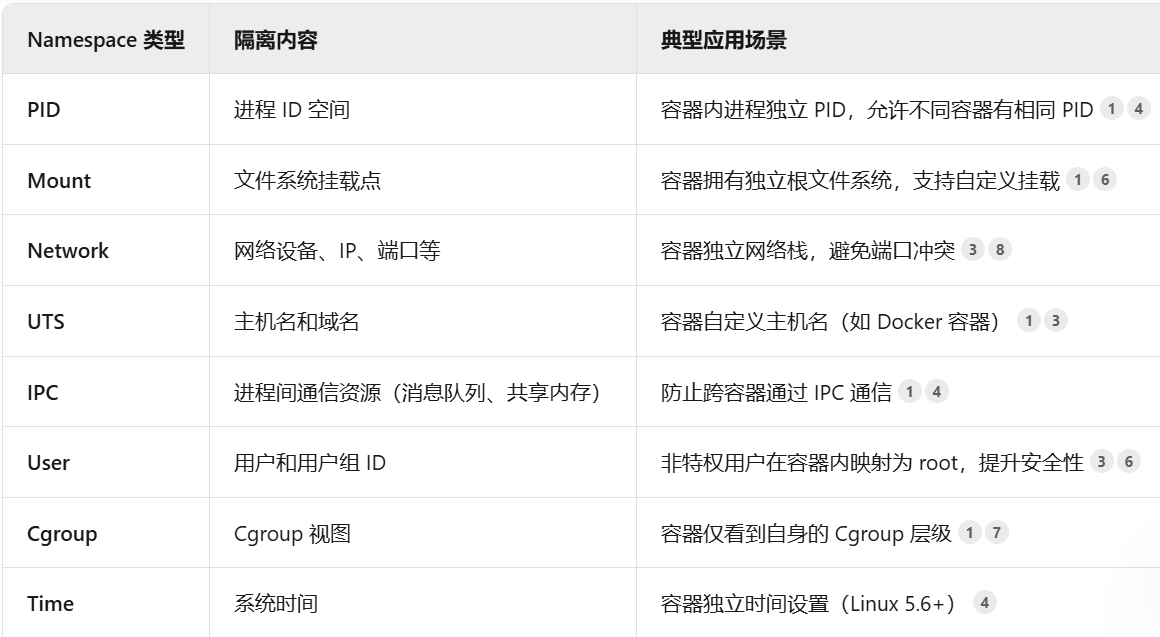
namespace:
namespace
namespace是==linux内核用来隔离内核资源的方式==。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
namespace实现的一个主要目的就是实现轻量级虚拟化服务(容器)

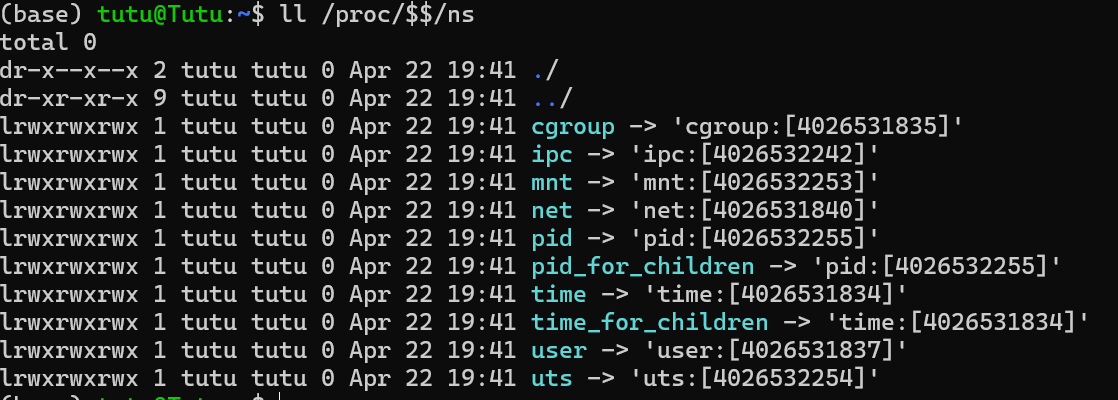
- 查看进程所属的namespace
systemd:Systemd 入门教程:命令篇 - 阮一峰的网络日志
Systemd 并不是一个命令,而是一组命令,涉及到系统管理的方方面面。
Systemd 可以管理所有系统资源。不同的资源统称为 Unit(单位)。
- Unit 一共分成12种。
- Service unit:系统服务 - Target unit:多个 Unit 构成的一个组 - Device Unit:硬件设备 - Mount Unit:文件系统的挂载点 - Automount Unit:自动挂载点 - Path Unit:文件或路径 - Scope Unit:不是由 Systemd 启动的外部进程 - Slice Unit:进程组 - Snapshot Unit:Systemd 快照,可以切回某个快照 - Socket Unit:进程间通信的 socket - Swap Unit:swap 文件 - Timer Unit:定时器
- Target 就是一个 Unit 组,包含许多相关的 Unit 。启动某个 Target 的时候,Systemd 就会启动里面所有的 Unit。从这个意义上说,Target 这个概念类似于”状态点”,启动某个 Target 就好比启动到某种状态。
docker利用cgroups实现资源隔离,利用namespace实现资源配额
沙盒工具:
- firejail:
- flatapk:
window sandboxie
容器技术:Containerization
容器技术
容器化是将软件代码与运行代码所需的操作系统 (OS) 库和依赖项进行打包,以创建可在任何基础架构上一致运行的单个轻量级可执行文件(称为容器)。
容器化架构

优点
- 轻量、拥有一个模具(镜像),既可以规模生产出多个相同集装箱(运行实例),又可以和外部环境(宿主机)隔离,最终实现对“内容”的打包隔离,方便其运输传送。
- 容器的目的就是提供一个独立的运行环境。
- 为了大大降低我们的计算成本,节省物理资源,提升计算机资源的利用率,让虚拟技术更加轻量化,容器技术应运而生。那么如何实现一个容器程序呢?我们需要先看看容器的基础架构。
- 容器(container)是一种更加轻量级的操作系统虚拟化技术,它将应用程序,依赖包,库文件等运行依赖环境打包到标准化的镜像中,通过容器引擎提供进程隔离、资源可限制的运行环境,实现应用与 OS 平台及底层硬件的解耦。
怎么实现在不同操作系统上的可移植性
容器和虚拟机的区别
https://www.redhat.com/zh/topics/containers/containers-vs-vms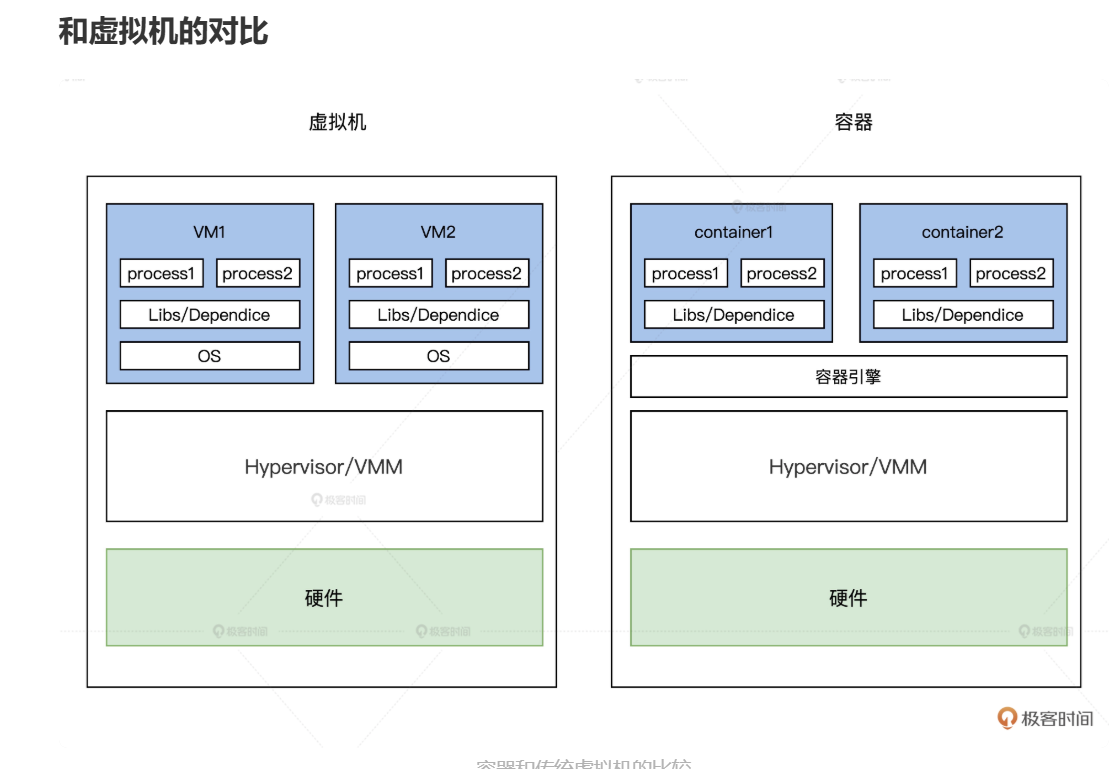


虚拟机:硬件虚拟化,由hypervisor虚拟化出一台服务器,两台服务器,三台服务器等等
容器:系统级虚拟化,处理进程隔离,而不是机器的隔离,通过namespace,cgroups实现
- 容器实际上只有程序和库,没有os,相对虚拟机更加轻便
- 访问第三方服务(云原生),可以仅仅部署该程序的副本,且在所有运行的容器进程中共享
- 允许更多的devops和持续交付
- 虚拟机:
- 基于系统级隔离,硬件虚拟化,通过Hypervisor(如VMware、Hyper-V)模拟完整的硬件环境。
- 每个VM运行独立的操作系统(Guest OS),完全隔离。
- 资源分配由Hypervisor管理。
- 容器:
- 基于轻量级进程隔离,依赖内核机制,共享宿主机的内核。
- 通过容器引擎(如Docker)利用宿主机的内核,无需独立OS。
- 使用命名空间(Namespaces)和控制组(Cgroups)实现进程、网络等隔离。
工作原理 基于Docker讲解
Docker解决了什么
[!NOTE]
最简单的例子就是日常开发中,我们clone下来一个代码想直接运行,会发现很多问题,即本地环境跟远端环境不一致。docker能将应用打包起来,搬到哪里都可以直接使用;
docker build 镜像
用当前操作系统文件与目录制作一个压缩包
这个包包含了这个应用运行所需的所有依赖
从而保证了本地环境和云端环境的高度一致
docker run 镜像创建一个“沙盒”来解压这个镜像,然后在“沙盒”中运行自己的应用
这个沙盒就是 Cgroups和Namespace (下文会讲)
容器实现的原理:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)
namespace
在使用 Docker 的时候,并没有一个真正的“Docker 容器”运行在宿主机里面。Docker 项目帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,Docker 为它们加上了各种各样的 Namespace 参数。这时,这些进程就会觉得自己是各自 PID Namespace 里的第 1 号进程,只能看到各自 Mount Namespace 里挂载的目录和文件,只能访问到各自 Network Namespace 里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝。不过,相信你此刻已经会心一笑:这些不过都是“障眼法”罢了。
问题:
虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为
mount namespace
https://www.cnblogs.com/f-ck-need-u/p/17718768.html
mount namespace隔离了各空间挂载进程实例,每个mount namespace的实例下的进程会看到不同的目录层次结构,每个namespace之间的挂载点列表是独立的,互不影响
实操:挂载1.iso到root mountnamespace,挂载2.iso到新建的mountnamespace
会发现两者的挂载点独立,互不影响
网络隔离
Bridge
如果 Docker 的容器通过 Linux 的命名空间完成了与宿主机进程的网络隔离,但是却有没有办法通过宿主机的网络与整个互联网相连,就会产生很多限制。
所以 Docker 虽然可以通过命名空间创建一个隔离的网络环境,但是 Docker 中的服务仍然需要与外界相连才能发挥作用。
每一个使用 docker run 启动的容器其实都具有单独的网络命名空间,Docker 为我们提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
在这一部分,我们将介绍 Docker 默认的网络设置模式:==网桥模式。==
在这种模式下,除了分配隔离的网络命名空间之外,Docker 还会为所有的容器设置 IP 地址。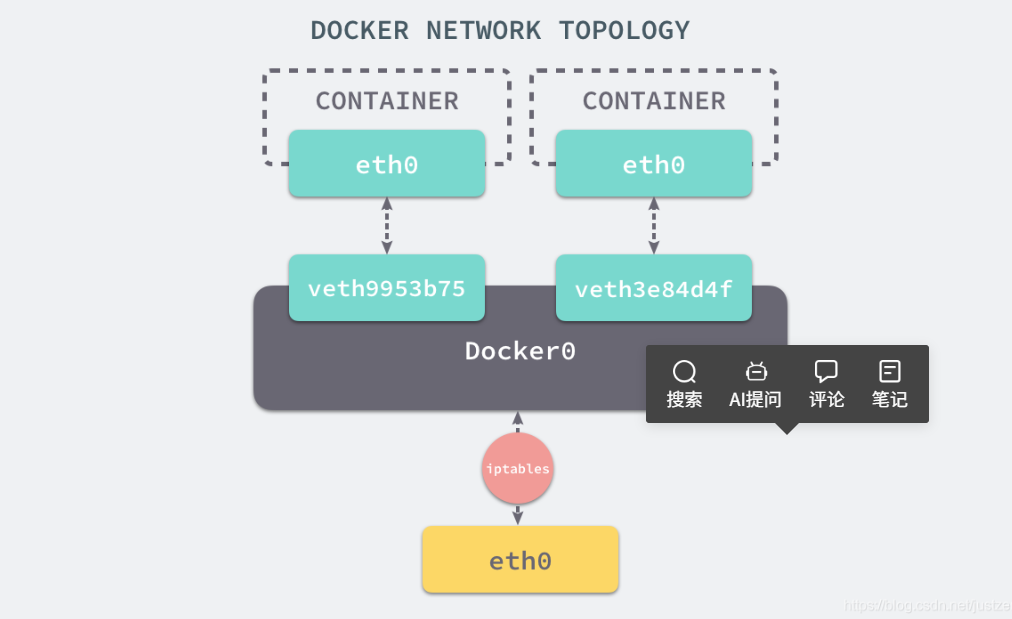
当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
在默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 ==docker0 网桥==中。
docker0会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。
网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
当有 Docker 的容器需要将服务暴露给宿主机器,就会为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则
cgroups
Cgroups是Linux内核中的一种机制,它可以将进程分组并为每个组分配特定的资源限制,例如CPU、内存、磁盘IO和网络带宽等。
通过Cgroups,系统管理员可以控制进程对资源的访问和使用,从而避免出现资源竞争和滥用的情况。Cgroups可以用于容器化应用程序,以限制容器中的进程对主机资源的访问。
chroot
- 使用Mount Namespace在容器进程启动之前重新挂载它的整个根目录“/”(挂在对宿主机不可见)
- 使用chroot改变进程的根目录到指定位置
- 为了能够让容器的这个根目录看起来更“真实”,我们一般会在这个容器的根目录下挂载一个完整操作系统的文件系统
- 挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)
volume机制
1 | |
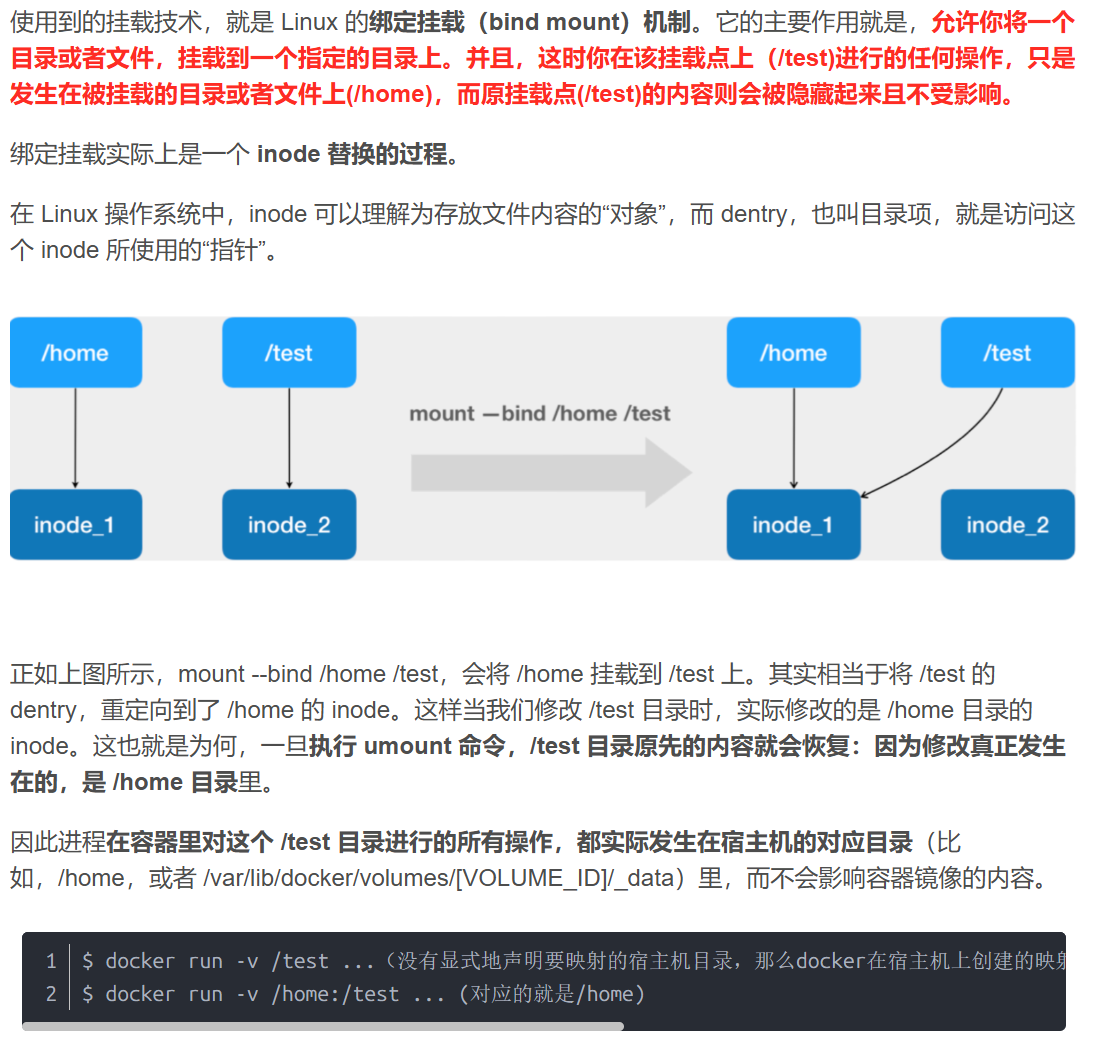
Docker是怎么做到把一个宿主机的目录和文件,挂载到容器里去的
. 尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。
而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/overlay2/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。
例子:把a绑定挂载到b上,当a被改动时,b也会被改动,umount后,b恢复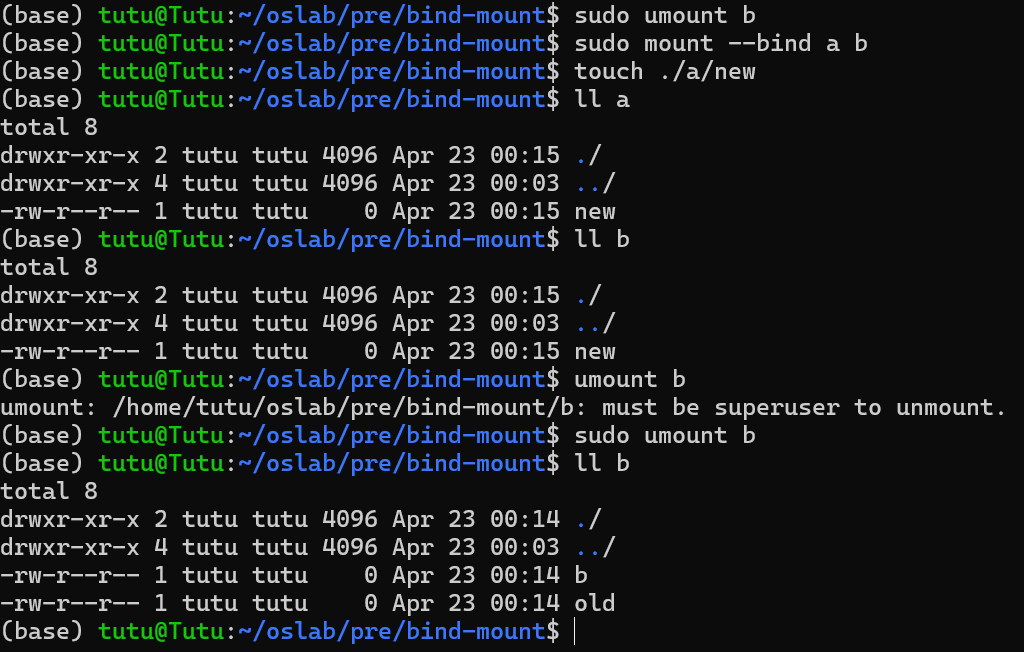
[!NOTE]
注意⚠️一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。所以一台机器上的所有容器共享宿主机操作系统的内核。
rootfs文件制作:layer与联合文件系统
https://blog.csdn.net/qq_33204709/article/details/129348791
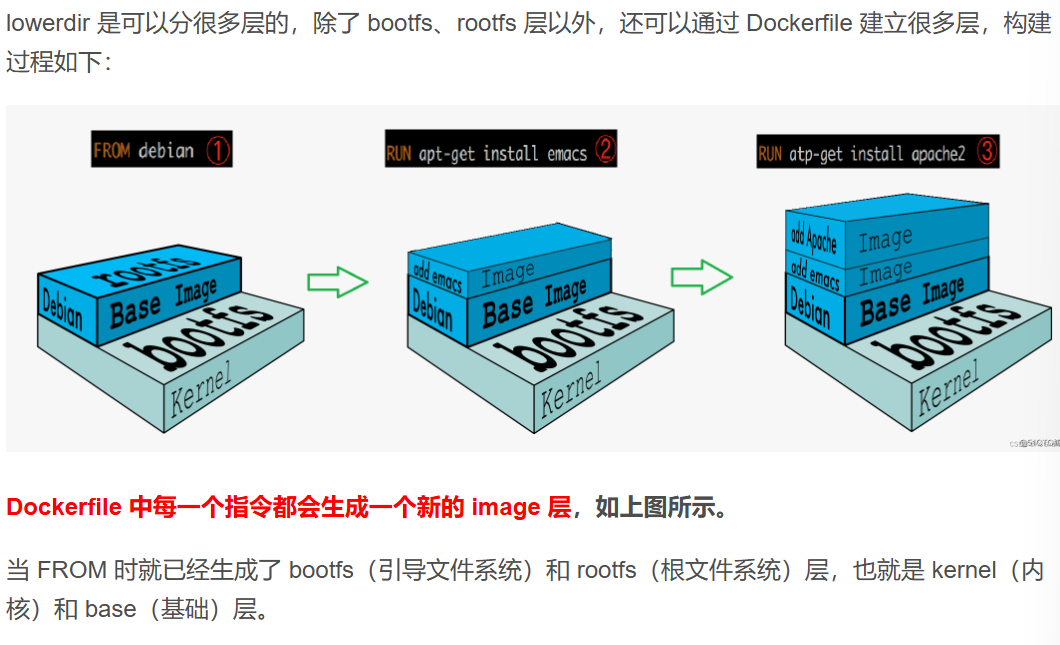
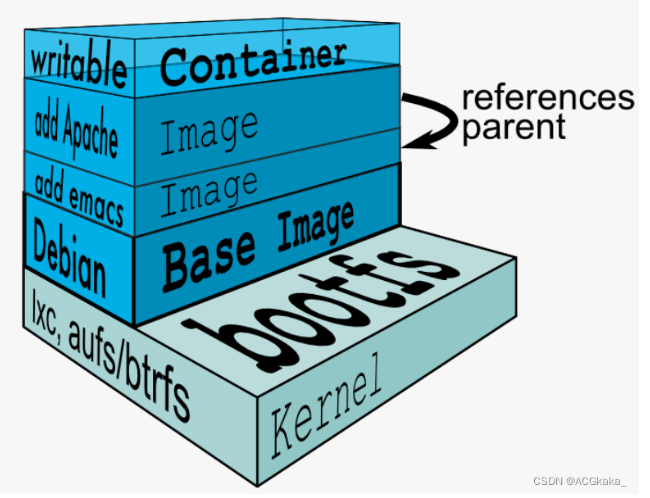
Docker 在镜像的设计中,引入了层(layer)的概念。
也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
Union File System
联合文件系统,将多个不同位置的目录联合挂载到同一个目录下(volume挂载的实现原理)
把a,b联合挂载到c上
unionfs联合了多个不同的目录,并把他们挂载到一个 统一的目录,当你对可读目录内容做出修改时,其结果只会保存到可写的目录下,不会影响可读的目录
将多个目录层(只读层和可写层)透明叠加为一个统一视图: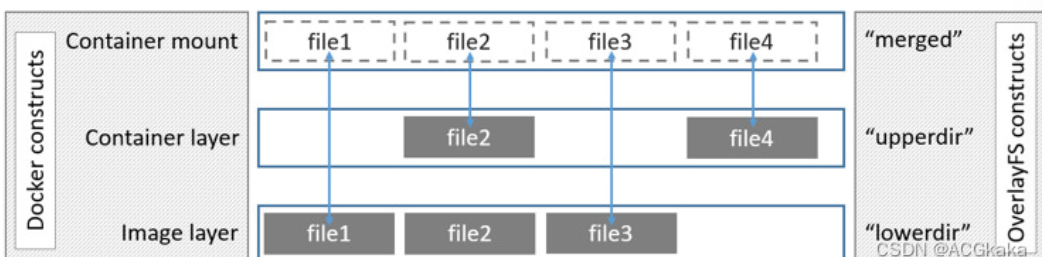
overlayFS 分层叠加,写时复制
- lowerdir(只读层):底层目录,可以是一个或者多个只读层,包括bootfs(引导文件系统)和rootfs层(根文件系统)
- upperdir(可写层):
upperdir层时 lowerdir 的上一层,只有这一层可读可写,其实就是 Container 层,在启动一个容器的时候会在最后的 image 层的上一层自动创建,所有对容器数据的更改都会发生在这一层。
- mergeddir(合并视图):最终用户看到的同一目录
overlay的工作流程:
将镜像各层作为 lower 基础层,同时增加 diff 这个可写层,通过 OverlayFS 的工作机制,最终将 merged 作为容器内的文件目录展示给用户。
在 Docker 中,Unionfs 技术被用于实现 Docker 镜像的分层存储和容器的文件系统。每个 Docker 镜像都由多个只读层级结构组成,这些层级结构可以使用 Union Mount 技术叠加在一起,形成一个可读写的容器文件系统。当容器中的文件被更改时,Docker 只需要在容器文件系统的顶层层级结构中进行更改,而不是在底层的只读层级结构中进行更改。这样可以保证 Docker 镜像的不可变性,并且可以更快地更新和部署容器。
1)读:
如果文件在 upperdir(container)层,直接读取文件;
如果文件不在 upperdir(container)层,则从镜像层(lowerdir)读取。
2)写:
首次写入: 如果 upperdir 中不存在,overlay 和 overlay2 执行 copy_up 操作,把文件从 lowerdir 层拷贝到 upperdir 层中,由于 overlayfs 是文件级别的(即使只有很少的一点修改,也会产生 copy_up 操作),后续对同一文件的再次写入操作将对已复制到 upperdir 层的文件副本进行修改,也就是常说的==写时复制(copy-on-write)。==
删除文件或目录: 当文件被删除时,在 upperdir 层创建 without 文件,lowerdir 层(镜像层)的文件时不会被删除的,因为它们是只读的,但 whiteout 文件会组织它们显示,当目录被删除时,在 upperdir 层(容器层)创建一个不透明的目录,这个和上边的 without 文件原理一样,阻止用户继续访问,image 层不会发生改变。
3)注意事项:
copy_up 操作只发生在文件首次写入,以后都是只修改副本;
overlayfs 只适用两层目录,相比于 AUFS,查找搜索都更快;
容器层的文件删除只是一个“障眼法”,是靠 without 文件将其遮挡,image 层并没有删除,这也就是为什么使用 docker commit 提交的镜像会越来越大,无论在容器层怎么删除数据,images 层都不会改变。
docker架构
https://blog.csdn.net/crazymakercircle/article/details/120747767
官方文档
https://docs.docker.com/get-started/docker-overview/
docker 常用指令
control docker with systemd
https://docker-docs.uclv.cu/config/daemon/systemd/
- 手动启动
systemctl start docker - http/https代理
创建一个名为/etc/systemd/system/docker.service.d/http-proxy.conf这将添加HTTP_PROXY环境变量:
1 | |
刷新更改:systemctl daemon-reload
重启docker:systemcel restart docker
连接容器的shell
创建一个容器并进入交互式模式:
docker contain run -it
在一个已经运行的容器里执行一个额外的command:
docker contain exec -it
映射容器的端口到主机端口
以nginx示例:
docker container run -p 80:80 nginx
拉取镜像
- pull from
registry(online) 从registry拉取- public(公有)
- private(私有)
- build from
Dockerfile(online) 从Dockerfile构建 - load from
file(offline) 文件导入 (离线)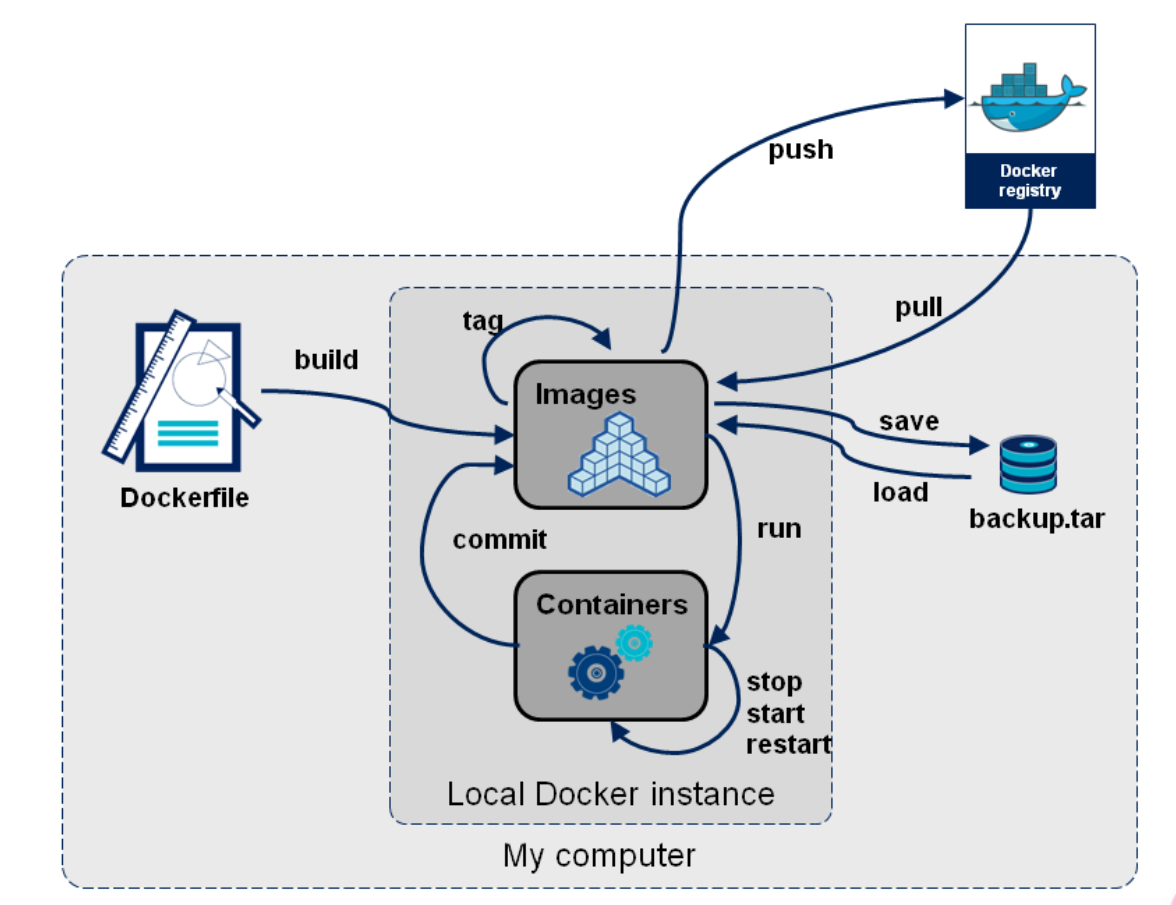
国内镜像源配置
1 | |
镜像的基本操作
1 | |
- 拉取镜像(默认拉取最新版本):docker pull nginx:版本
- 查看镜像:docker image ls
- 删除镜像:docker image rm 镜像名
- 从离线文件导入镜像:docker image load -i 路径/文件名
dockerfile 自己构建一个docker 镜像
https://docs.docker.com/reference/dockerfile/
- Dockerfile是用于构建docker镜像的文件
- Dockerfile里包含了构建镜像所需的“指令”
- Dockerfile有其特定的语法规则
docker容器的导入导出
docker expert 容器名 > 导出的路径/tar包名称
docker import/load tar包
- docker import:丢弃了所有的历史记录和元数据信息,仅保存容器当时的快照状态。在导入的时候可以重新制定标签等元数据信息。
- docker load:将保存完整记录,体积较大。
docker volume
对docker容器的更改只发生在只读层,容器停止,只读层就会被丢弃,所以改动数据会丢失
解决方法:使用docker volumes将宿主机数据卷挂载到容器内的数据目录
docker volume create data_volume
docker run -v data_volume:/var/lib/postgres postgres
docker compose
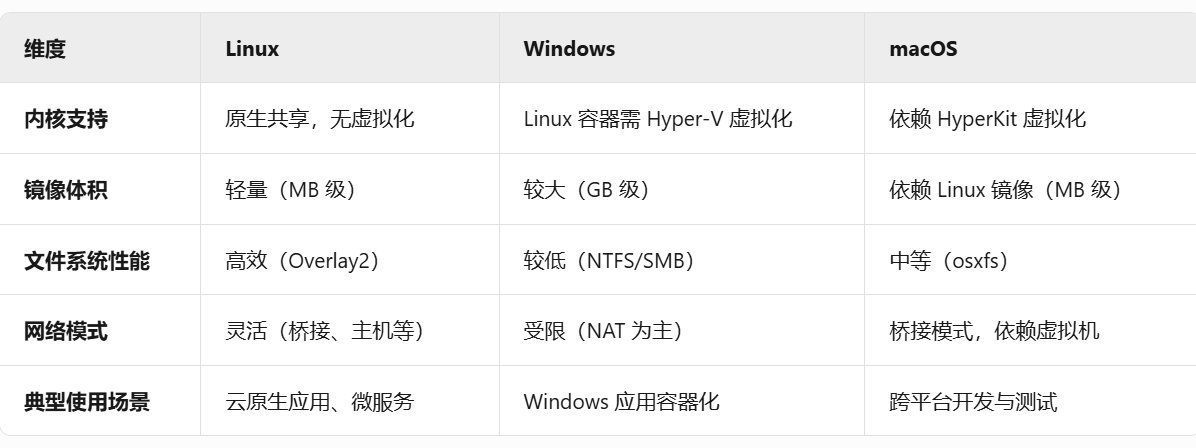
docker在linux windows mac下的底层实现有何不同
多容器 docker-compose k8s
问题
沙盒 容器有什么区别
我的理解:沙盒更侧重于程序和系统的隔离,把通过把应用程序隔离在一个受限的环境中