李宏毅-人类语言处理
https://speech.ee.ntu.edu.tw/~hylee/ml/2022-spring.php
-

-
-

- RNN GNN 补充深度学习没有学到的地方
机器学习 sequence补充
self-attention
输入是一个sequence且长度会改变
- 句子的表示[ 词汇 词汇 词汇 ] 词汇用vector表示
- word embedding 给每一个词汇一个向量,一个句子就是一排长度不一的向量(frame)
- 图也是一个向量的组合,每个node是一个向量
输出类型 - 输入输出数量一样:每个向量都有一个对应的label,比如每一个词汇要对应什么样的词性的任务(词性标记),或者决定每个语音词对应的phenoic
- 输入一串向量(sequence),输出一个向量:分析句子的性质(pos,neg),分析一段声音是谁讲的
- 不知道要输出多少label,输入n,输入n:S2S,sqe2seq,比如翻译,语音辨识
sequence labeling 输入=输出
用一个全连接层
问题,你想说一个词是saw,但是词性有两种,动词和名词,输出不会不一样,因为输入都一样。
解决,给一整个window的信息,让model考虑上下文
但是这样信息太少,如果有需要一整个Seq的词就运算量太大,还容易过拟合??
解决->自注意力机制
自注意力机制 每个vector都考虑了整个seq的咨询
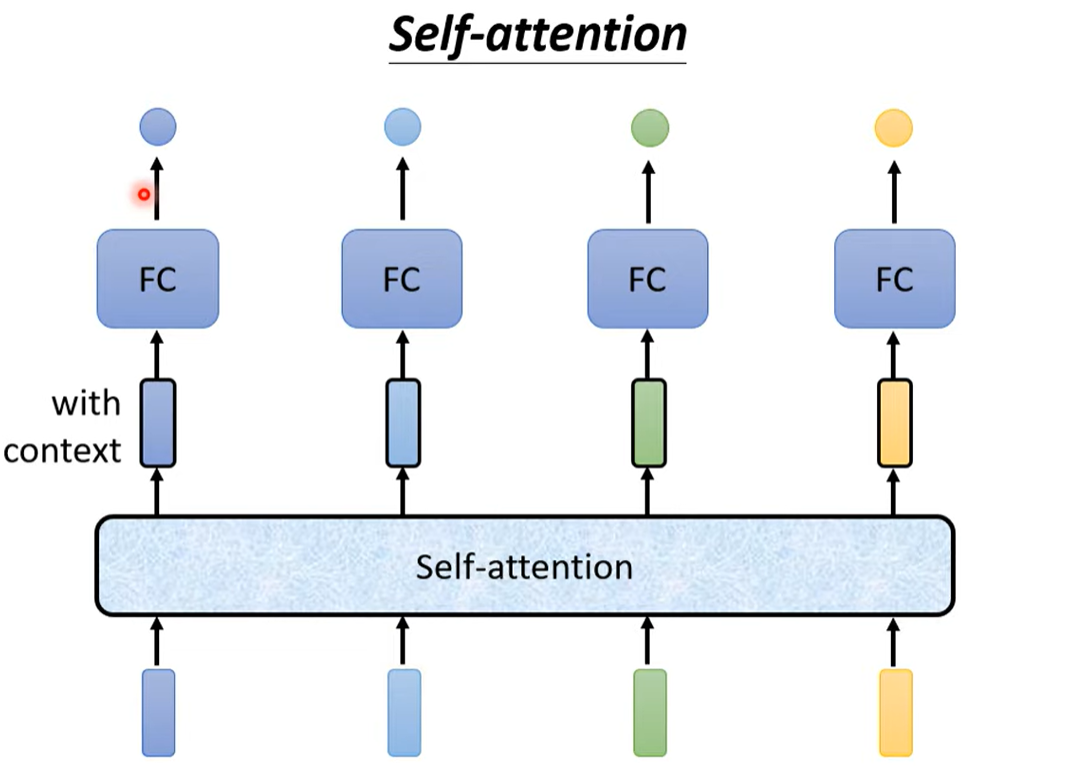
self-attention层可以多次叠加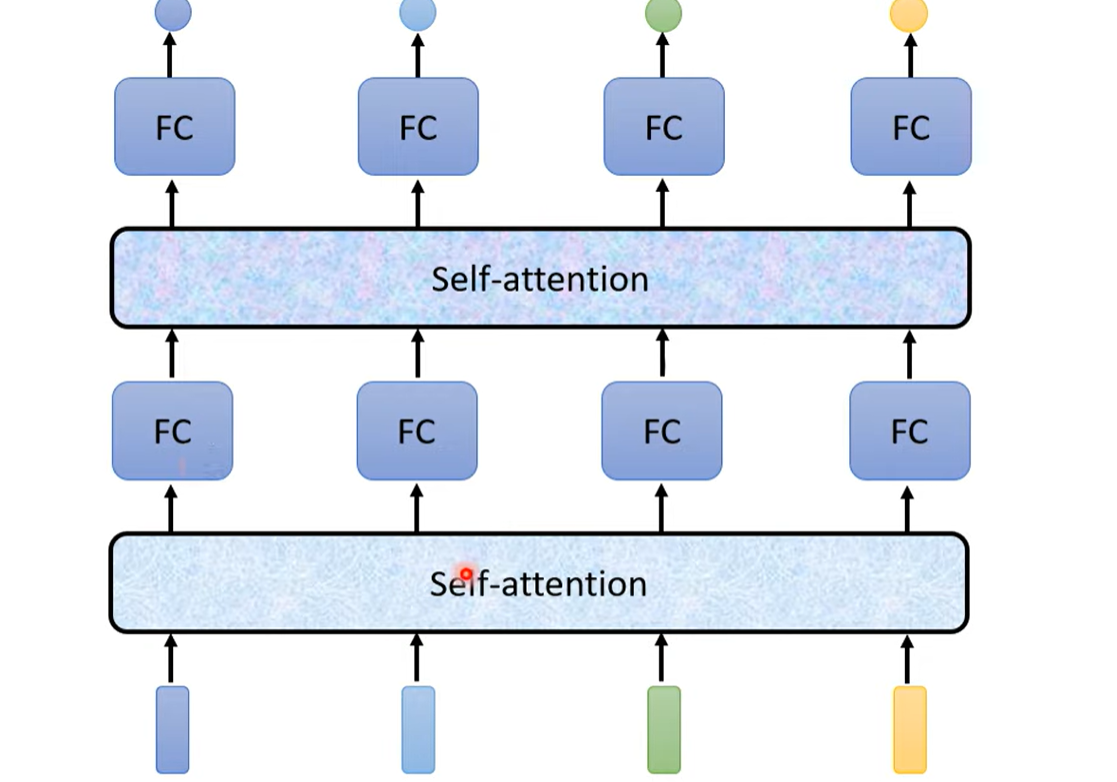
input:一串向量Ax
output:另外一串向量Bx(每个B都是考虑每个A产生的)
Bx是怎么由Ax生成的?
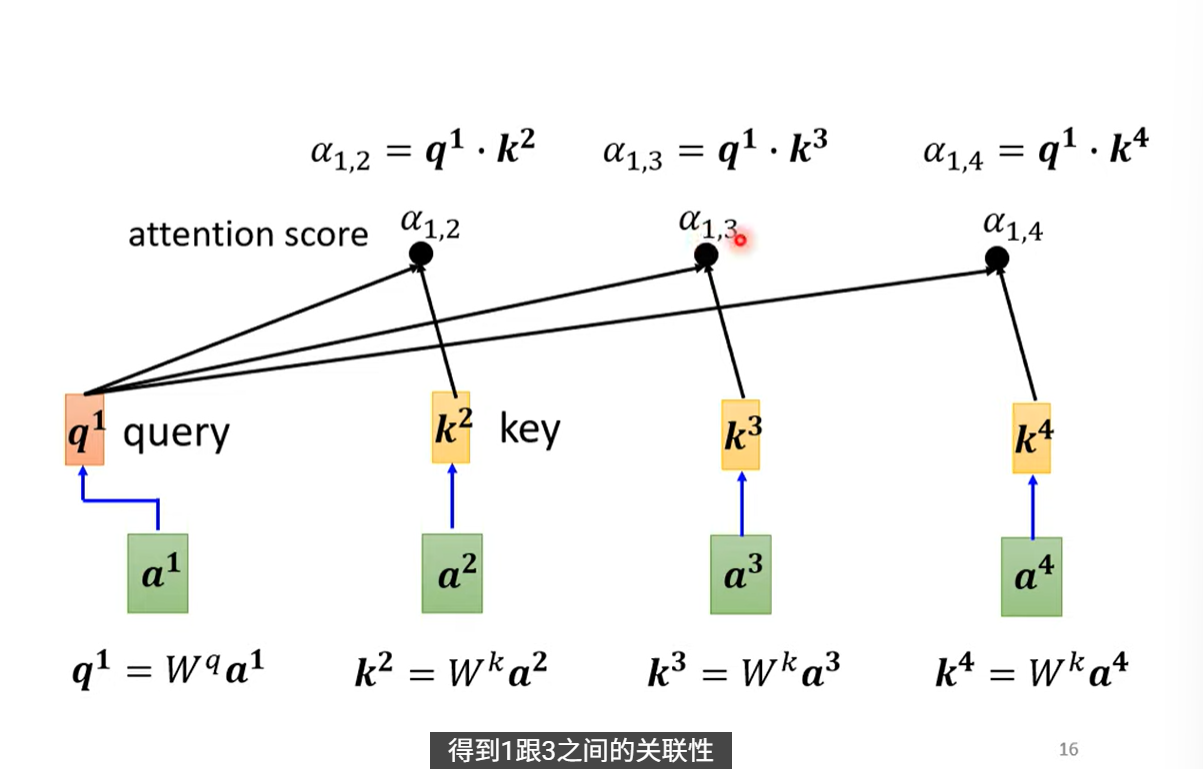
先判断整个seq里哪些vector(a)跟a1有关系,- - ==用阿尔法表示a1与a的关系程度==
求阿尔法:
dot-product:点积法,最常用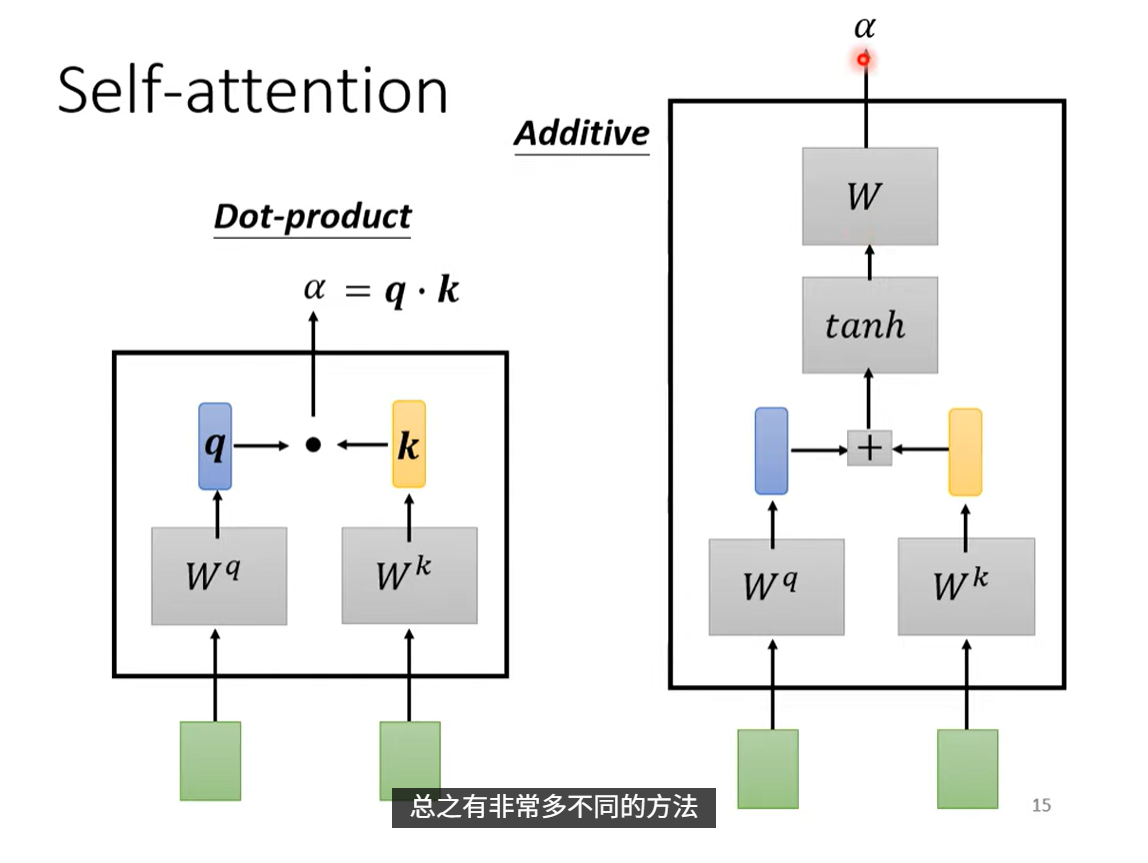
- 分别计算a1与a2,a3,a4的相关性,在实操的时候a1求 与自己 的关联性阿尔法1,1
- 做一个softmax,输出是一排向量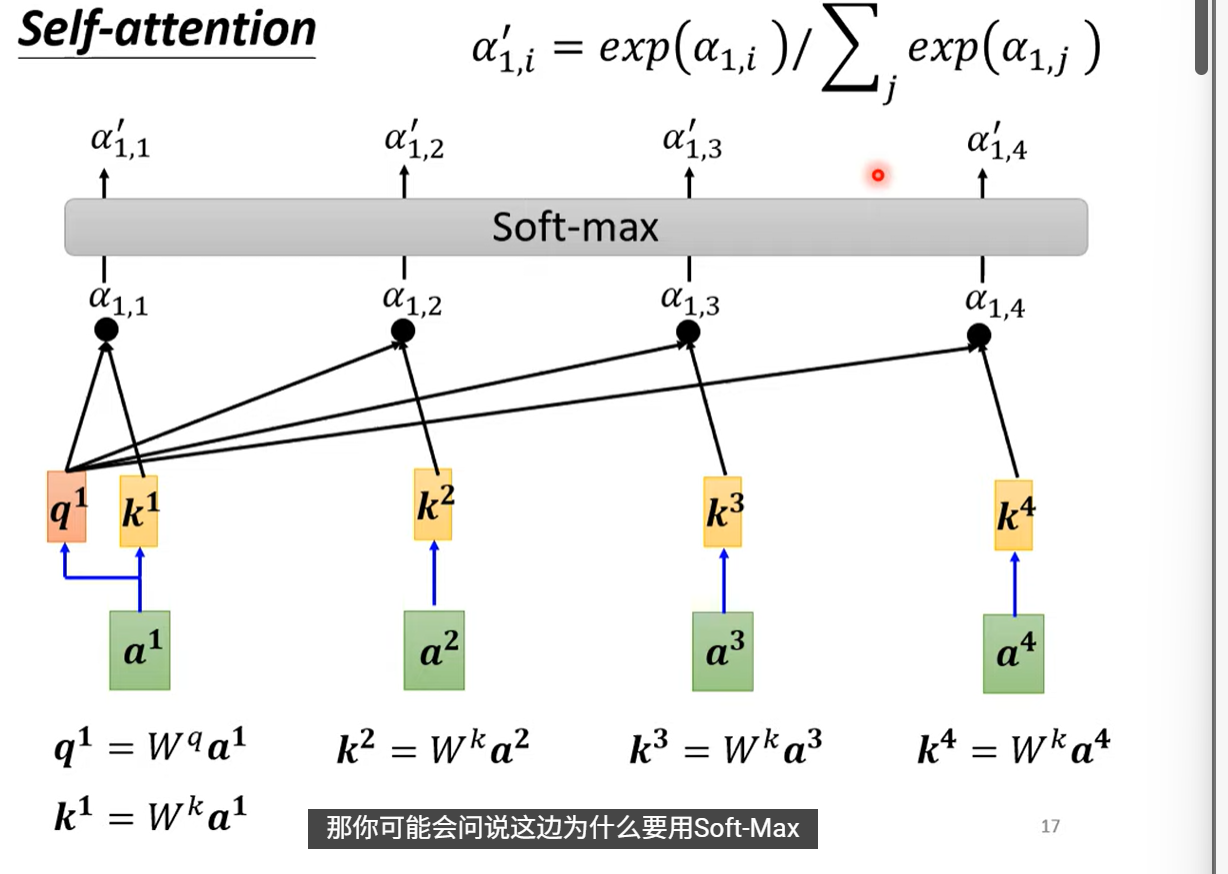
- 根据关联性数组抽取seq中的重要vector
- 如果跟a1的关联性特别高,那么b1就会特别像a2(假设这里a1,a2的关联性特别高)
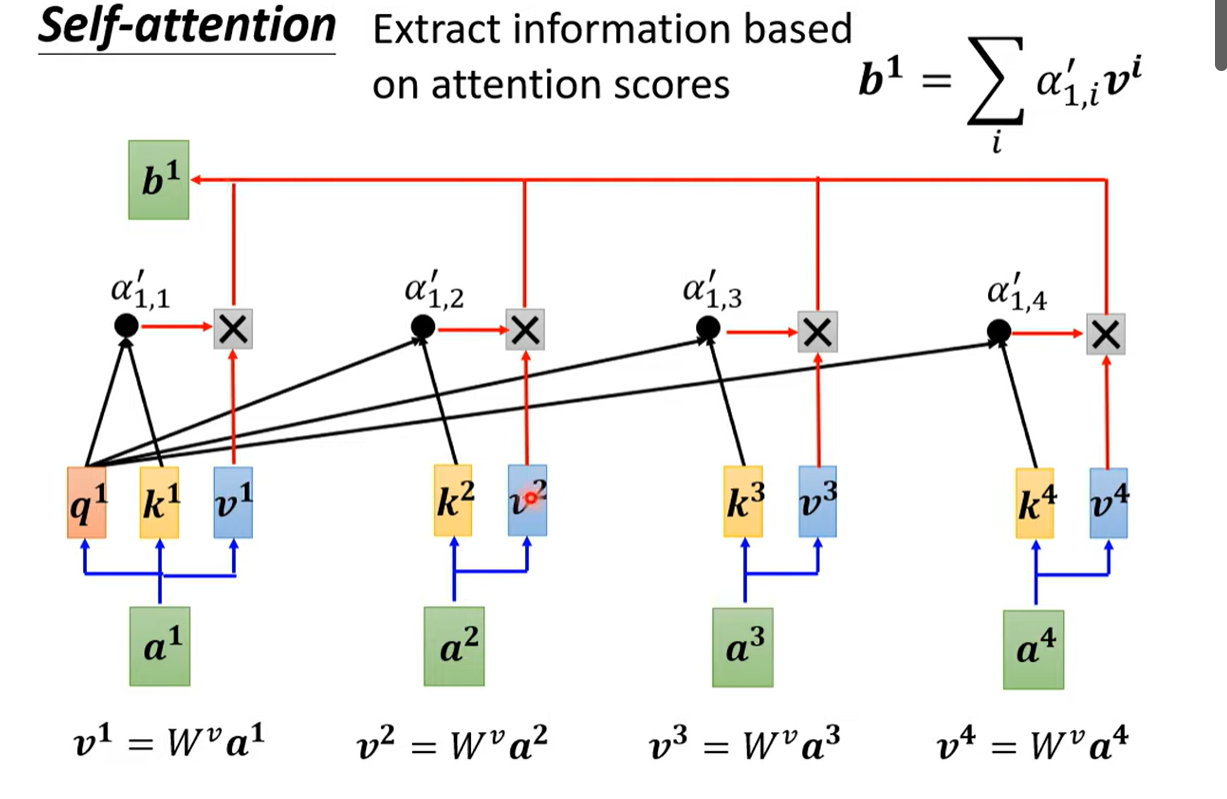
- 如果跟a1的关联性特别高,那么b1就会特别像a2(假设这里a1,a2的关联性特别高)
语音识别
总览
输入:声音,一串向量
输出:一系列token
输入>>输出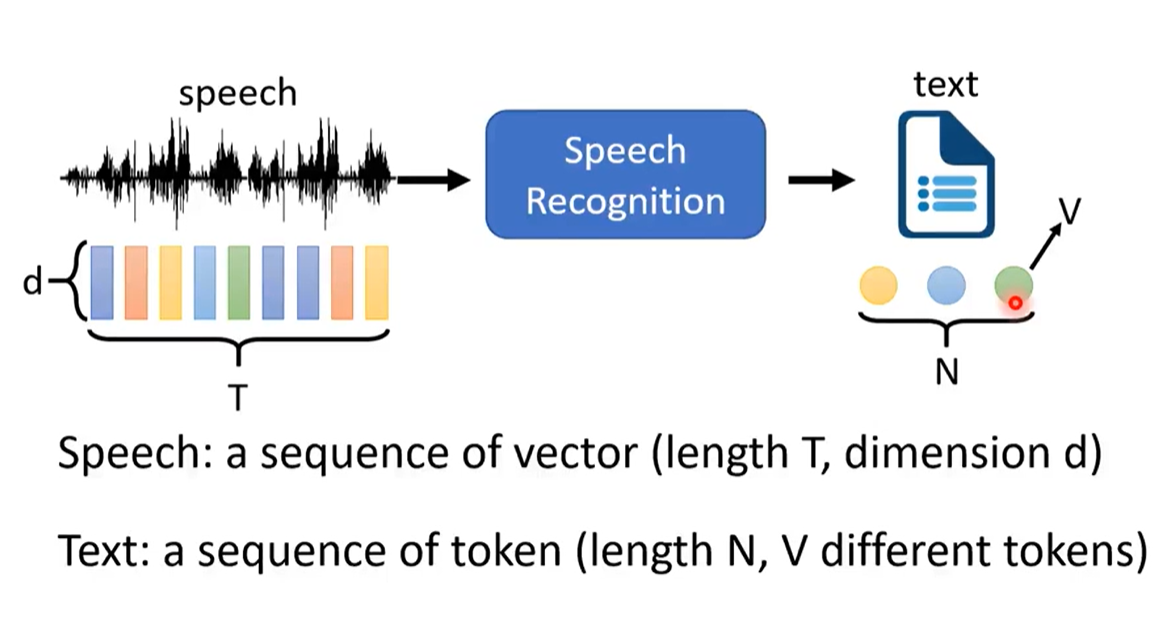
- 输入:token
- phoneme 发音的基本单位
- lexicion:记录了文字和phoneme的关系
- grapheme 书写的基本单位(比如26个英文字母+{ __ }(space)+标点符号
- 中文的graphem没有空白space
- word 词汇
- 英文有空白分割词汇,中文没有,而且词汇的V会非常大,一个语言会有很多词汇,有的语言没法穷举词汇
- morpheme 有含义的基本单位
- unbreakable->un break able
- rekillable re kill able
- bytes

- phoneme 发音的基本单位
- 输出:
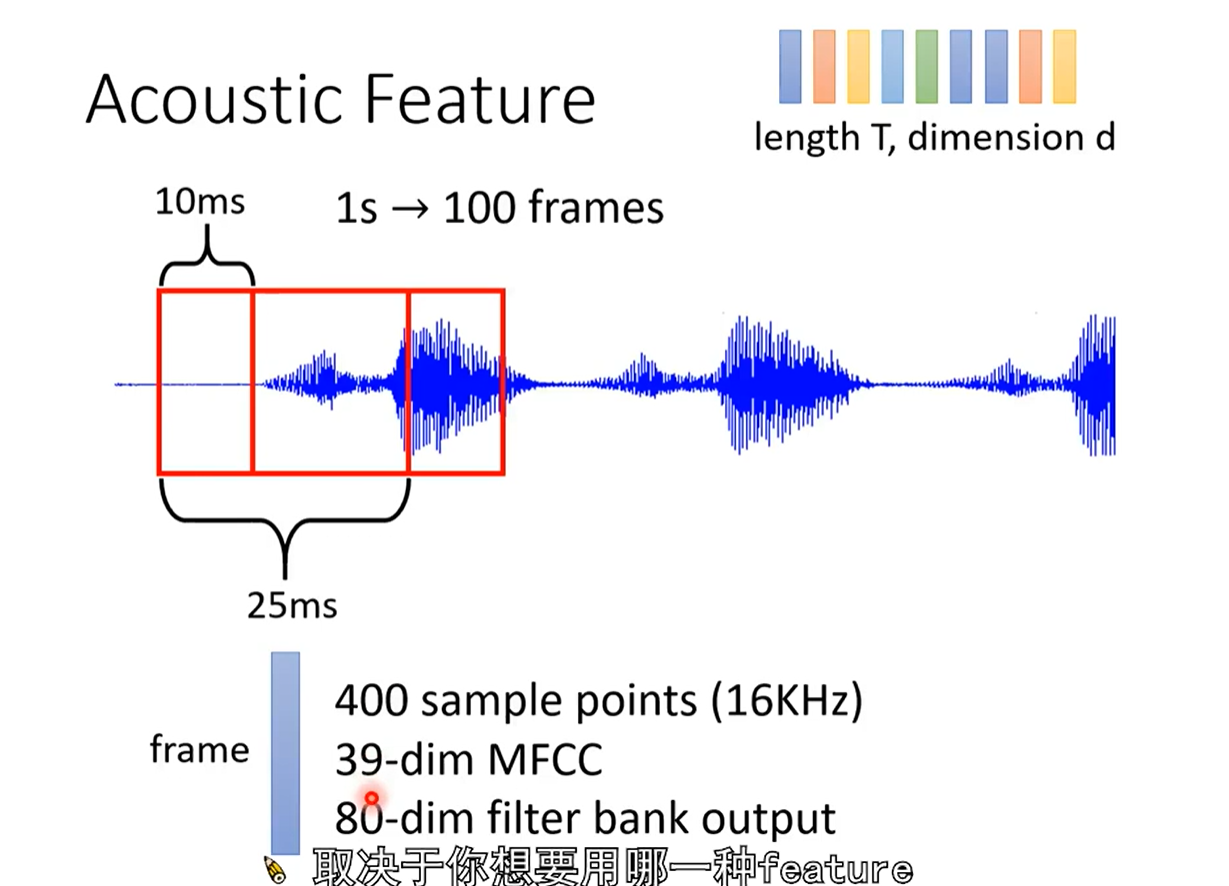
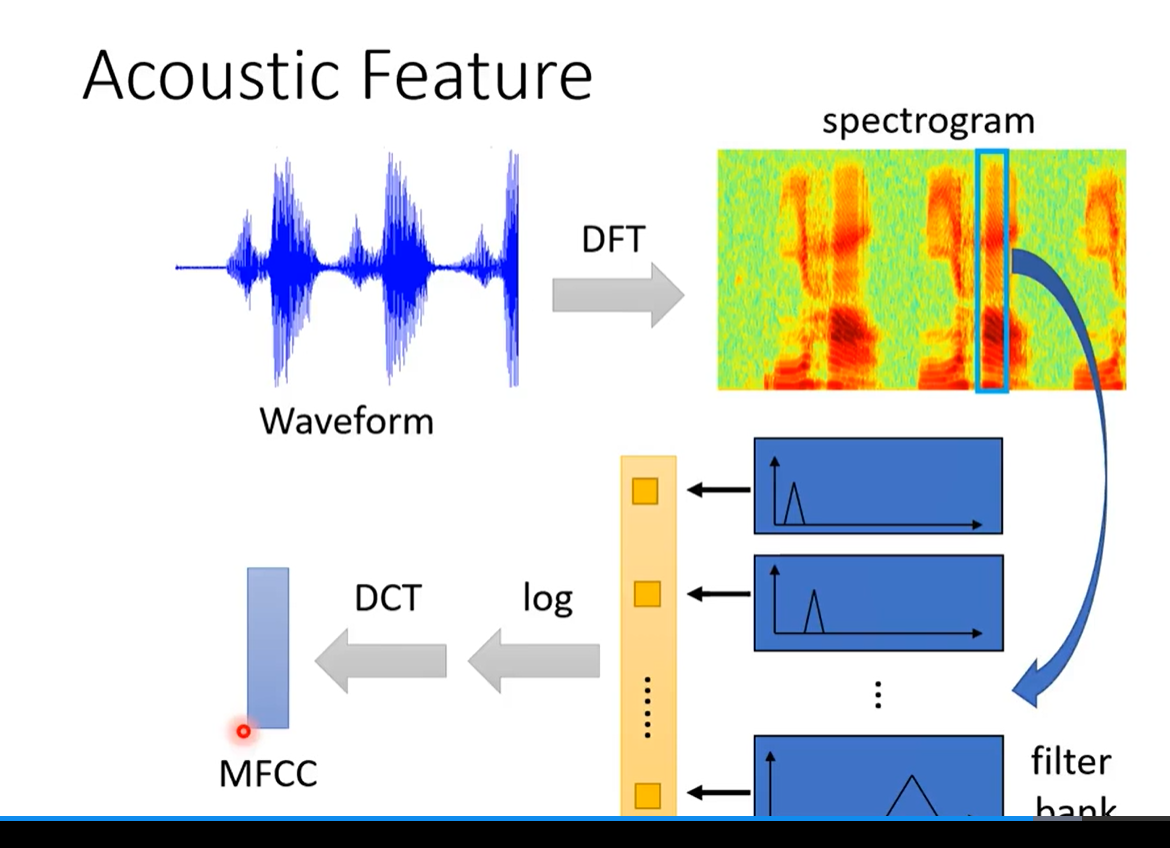
- 怎么给输入进行处理
LAS(listen ,attend ,and spell)
- listen encoder
- 去除杂讯,抽出