Reliable AI Lab
从理解DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning这篇论文的LLM+RL+GRPO技术原理开始,结合VeRL github工程项目进行学习,参考网址:
- VeRL官方github框架:https://github.com/volcengine/verl。
- GRPO复现方式:https://verl.readthedocs.io/en/latest/algo/grpo.html
deepseek-r1 论文阅读网址DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
强化学习
(32 封私信 / 80 条消息) 强化学习入门:基本思想和经典算法 - 知乎
https://www.ibm.com/cn-zh/think/topics/reinforcement-learning
强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。
强化学习主要有以下几个特点:
- 试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy)。
- 延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
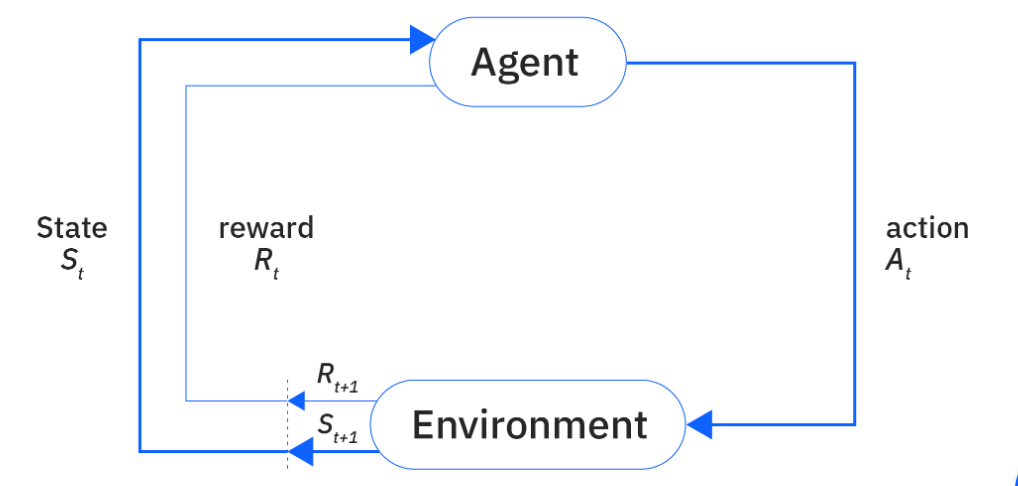
基本元素
环境(Environment):
是一个外部系统,智能体处于这个系统中,能够感知到这个系统并且能够基于感知到的状态做出一定的行动。
状态(State)/观察值(Observation):
状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。
动作(Action):
不同的环境允许不同种类的动作,在给定的环境中,有效动作的集合经常被称为动作空间(action space),包括离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces),例如,走迷宫机器人如果只有东南西北这 4 种移动方式,则其为离散动作空间;如果机器人向 360◦ 中的任意角度都可以移动,则为连续动作空间。
奖励(Reward):
是由环境给的一个标量的反馈信号(scalar feedback signal),这个信号显示了智能体在某一步采 取了某个策略的表现如何。
相关术语:
- 策略

- 状态转移

- 回报

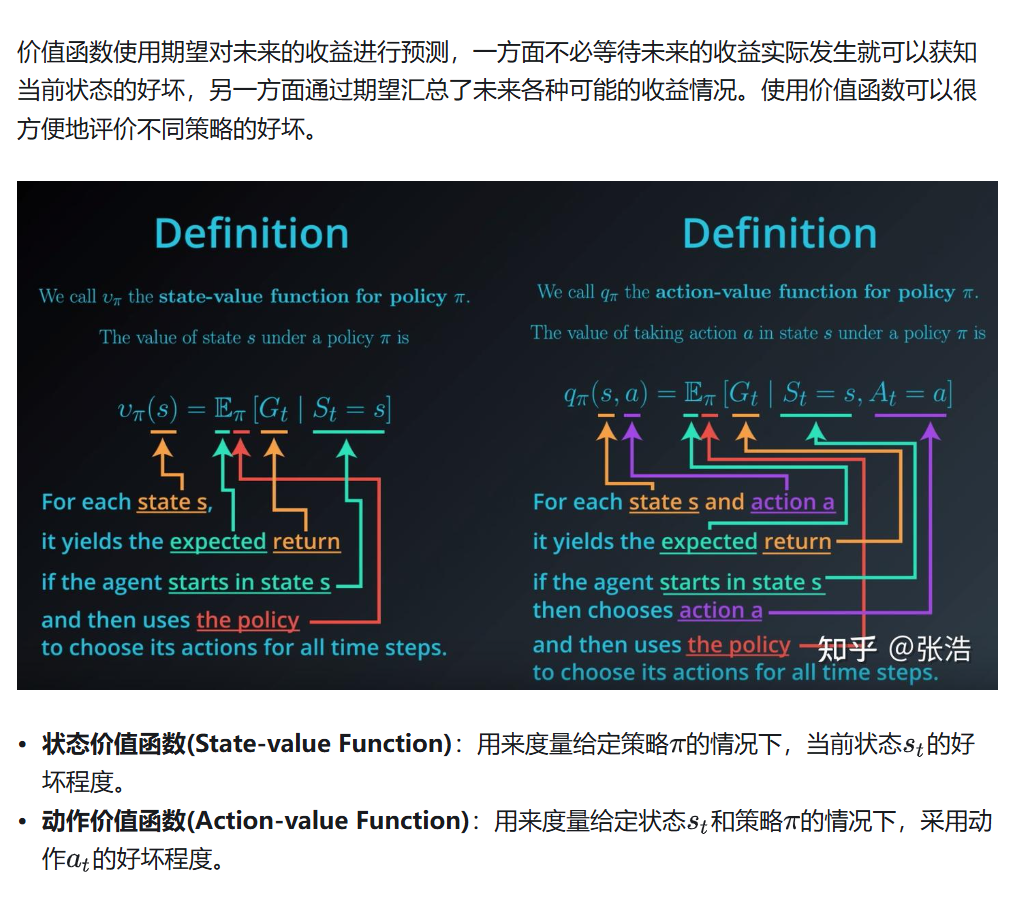
- 价值函数
马尔可夫决策过程

以下为上述术语的详细解释
【【大白话03】一文理清强化学习RL基本原理 | 原理图解+公式推导】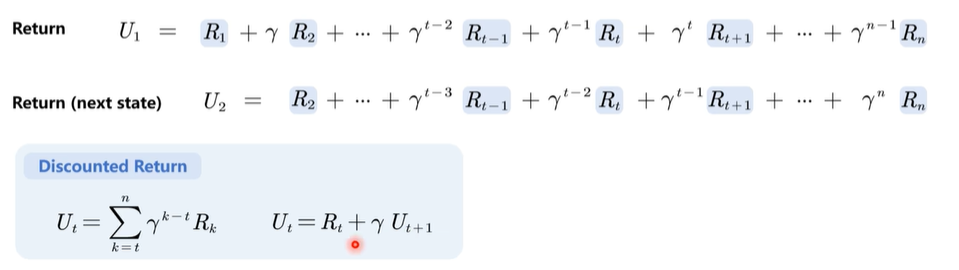
小写为现以观测到的状态,大写为将来状态
折扣汇报:未来的奖励不如现在的重要,用折扣率(0,1] 取得折扣回报
不同状态(st,st+1)对应的折扣回报是递推的关系,st我们称为及时奖励,st+1称为未来奖励
状态价值函数 行为价值函数

value-based || policy-based
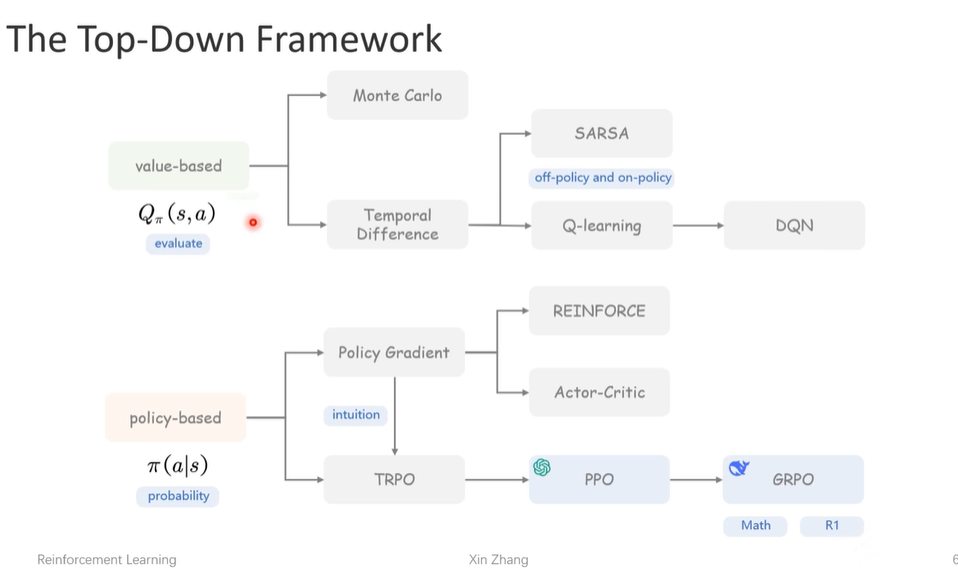
value-based
- 怎么估计Qpi(s,a):

时序差分

TD算法的应用:
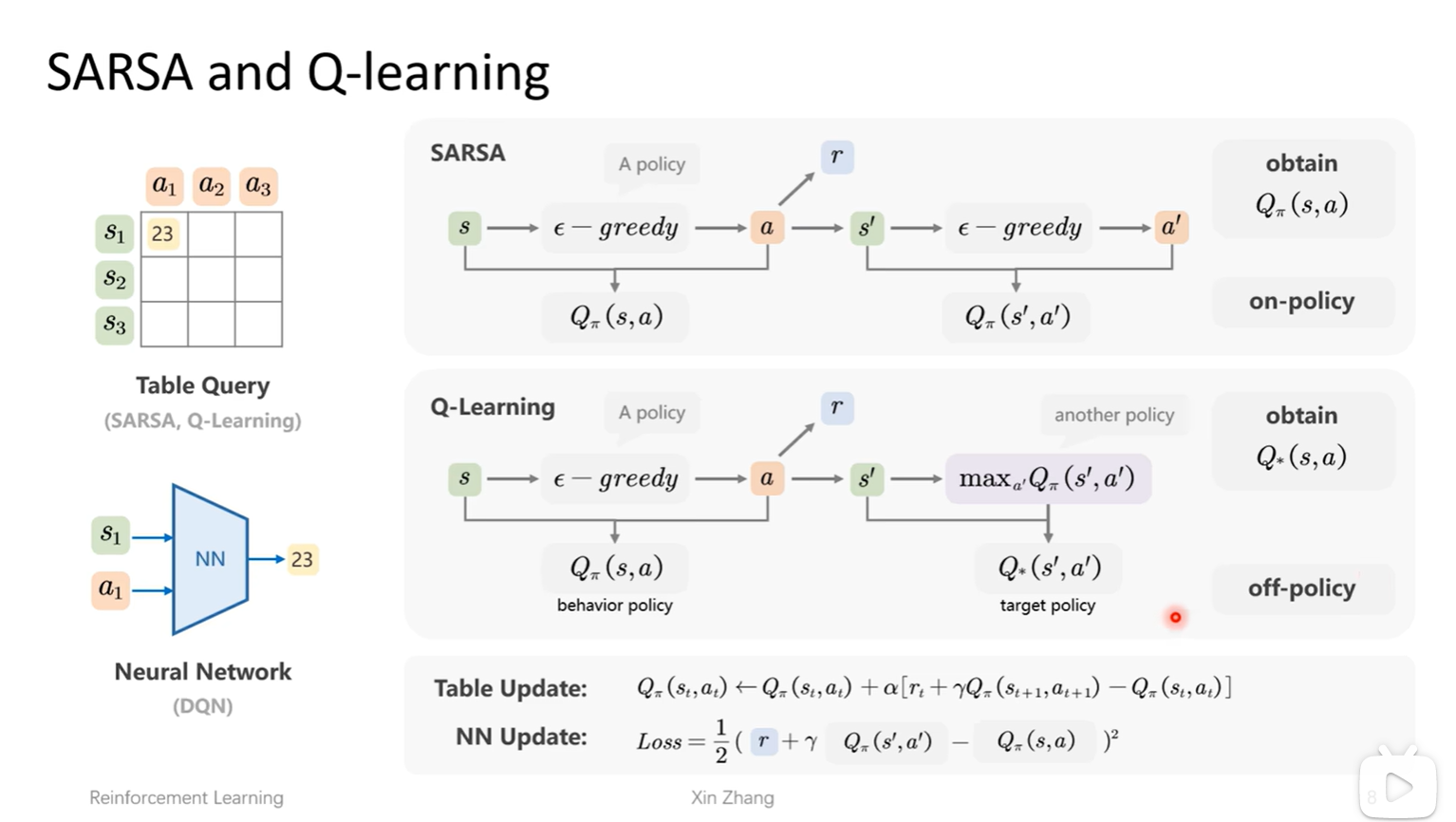
- sarsa算法:同策略
- q-learing:异策略
policy-based
策略梯度

策略梯度的应用

TRPO
希望模型越学越好,期望越来越大,希望新策略比老策略好
注意以下的推理过程,如何推出优势函数,状态转移用老策略近似,动作分布用重要性采样(新策略概率值/旧策略概率值)近似

kl散度
PPO
对trpo进行改进,使其计算变得
- 增加惩罚项
- 截断

广义优势估计:对多步的优势进行综合考虑
GRPO
从PPO算法演变而来
- ppo
- 用最大化以下函数来优化策略模型
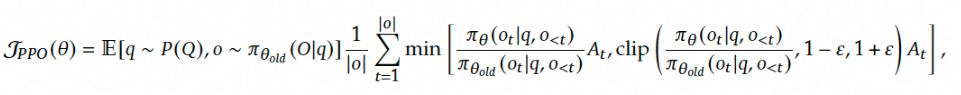
- 用最大化以下函数来优化策略模型
算法
监督微调SFT
(32 封私信 / 80 条消息) 【万字详解】SFT 是什么?大模型SFT(监督微调)该怎么做(经验技巧+分析思路) - 知乎
- 概念:在预训练模型基础上,通过少量标注数据调整模型参数,使其适应特定任务的技术。
- 核心思想:“迁移学习” 利用预训练模型已有的知识(如语言理解能力),通过微调快速适配新任务(如文本分类、对话生成)。
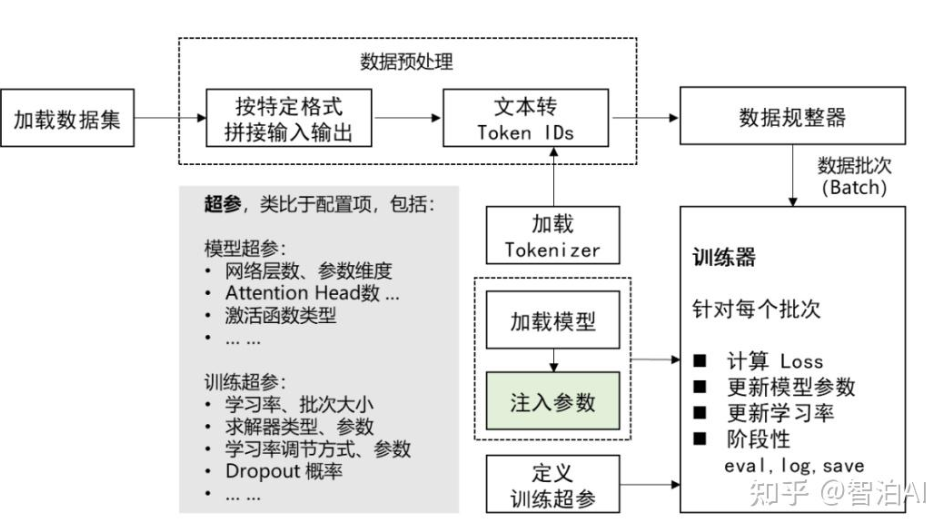
术语
special token: pretrain 阶段完全没见过的 token,在sft 阶段会被赋予全新的语义。主要用于标注对话的角色: user、assistant、system 这些。
实现原理
- 数据构造
- 给promt和answer 给模型提供一个类似于问答模式的答案来学习
- 需要生成mask向量来屏蔽不希望计算loss的部分,answer部分为1,其余部分为0
- 构造好输入后,token转为embedding,经过transformer的过程跟之前预训练完全一样,也就是我们又得到了一个维度是
(1,10,vocab_size)的输出logits=output_layer(transformer(X)),进一步就可以计算answer部分的loss了,其实就是通过mask把不希望考虑的地方乘以0,保留answer部分loss。
CoT
【DeepSeek-R1背后的技术】系列六:思维链(CoT)_deepseek cot-CSDN博客
概念:Chain-of-Thought (CoT) 是指模型在输出最后答案之前,会以自然语言的形式生成思路或推理链,使得结果对于人类更具可解释性。
一个完整的包含CoT的Prompt往往由指令,逻辑依据和示例三部分组成
- 指令:用于描述问题并且告知大模型的输出格式;
- 逻辑依据:指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识;
- 示例:指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
研究人员和从业者可以确保在不同的应用程序中负责任和有效地部署 CoT 提示。
deepseek-r1内置了cot的输出格式
模型蒸馏
- 数据蒸馏
-用< q,a >pair训练小模型,可以用sft训练 - logits蒸馏
应用softmanx函数之前的原始输出分数,引用温度系数T,用于调整教师模型输出的软标签的概率分布- 教师模型的输出经过温度调整后的公式为
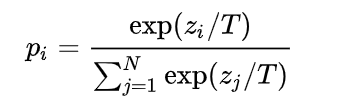
- zi时教师模型的logits输出,训练学生模型时温度调整,然后用一个损失函数来评估学生模型和教师模型输出之间的差异。

- 总损失函数通常是蒸馏损失和交叉熵损失的加权和:

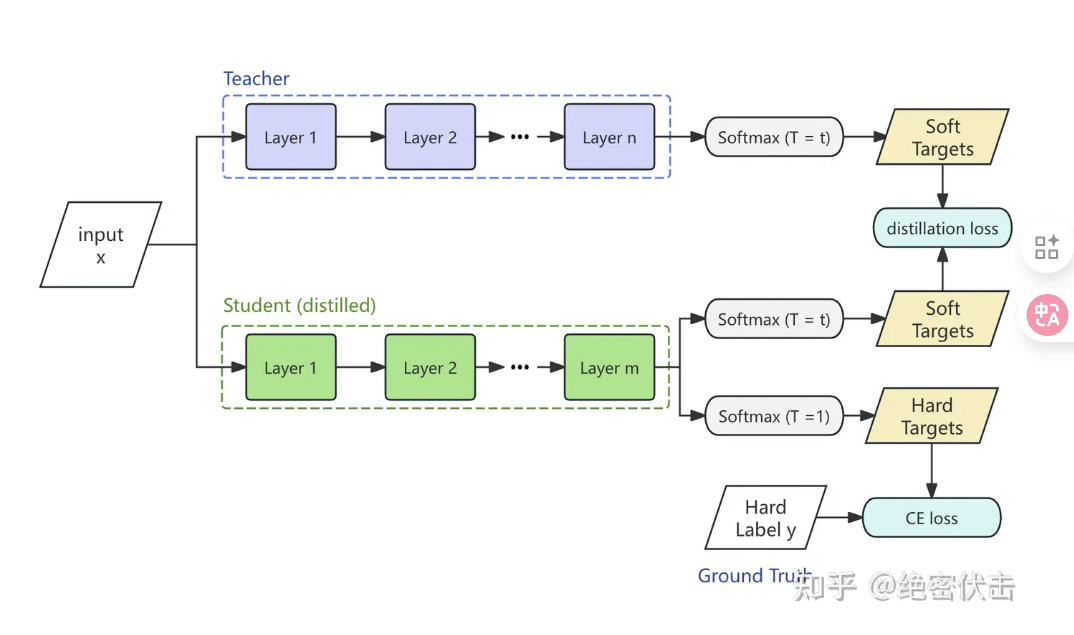
- 教师模型的输出经过温度调整后的公式为
- 特征蒸馏
- 对中间层进行蒸馏
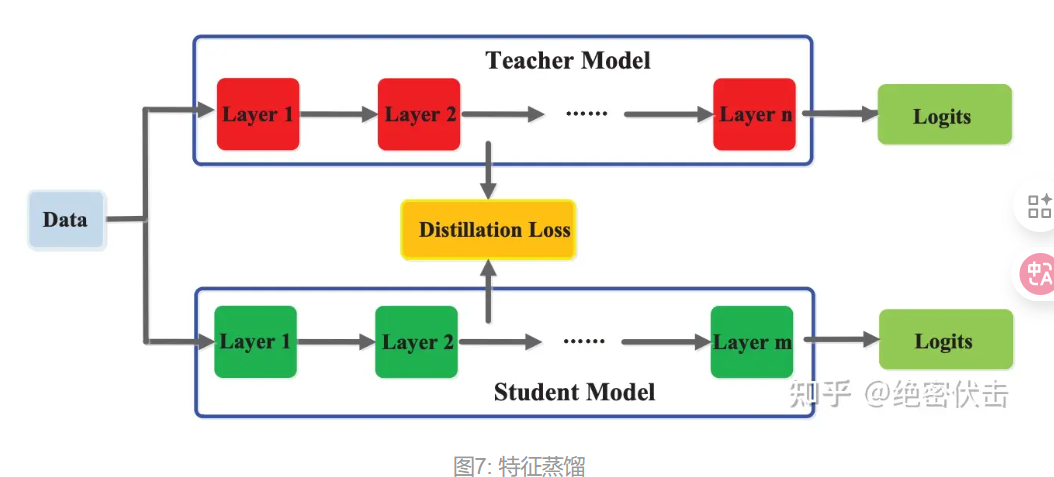
- 对中间层进行蒸馏